

[데이터베이스] Elasticsearch란?
cs-study에서 스터디를 진행하고 있습니다.
Elasticsearch란?
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈 소스 분산 검색 엔진이다. Elasticsearch를 통해 루씬 라이브러리(Java에서 개발한 정보 검색용 라이브러리)를 단독으로 사용할 수 있으며, 방대한 양의 데이터를 신속하게(거의 실시간) 저장, 검색, 분석을 수행할 수 있다.
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며, ELK(Elasticsearch / Logstash / Kibana) 스택으로 사용되기도 한다. ELK 스택은 다음과 같다.
- Logstash
- 다양한 소스(DB, csv 파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
- Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계하여 필요한 정보를 획득
- Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
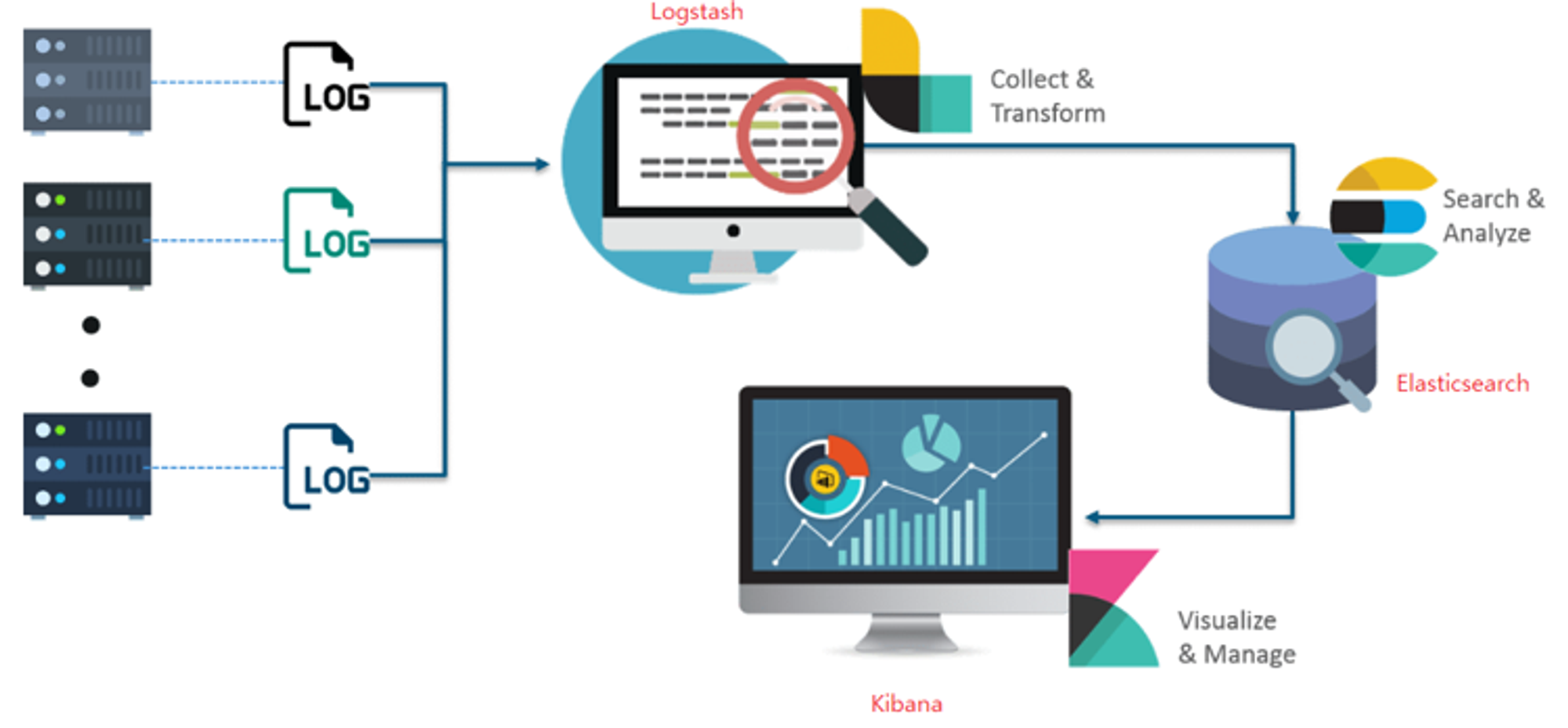
주로 ELK는 로드밸런싱되어 있는 WAS의 흩어져 있는 로그를 한 곳으로 모으고, 원하는 데이터를 빠르게 검색한 뒤 시각화하여 모니터링하기 위해 사용한다.
Elasticsearch vs RDB
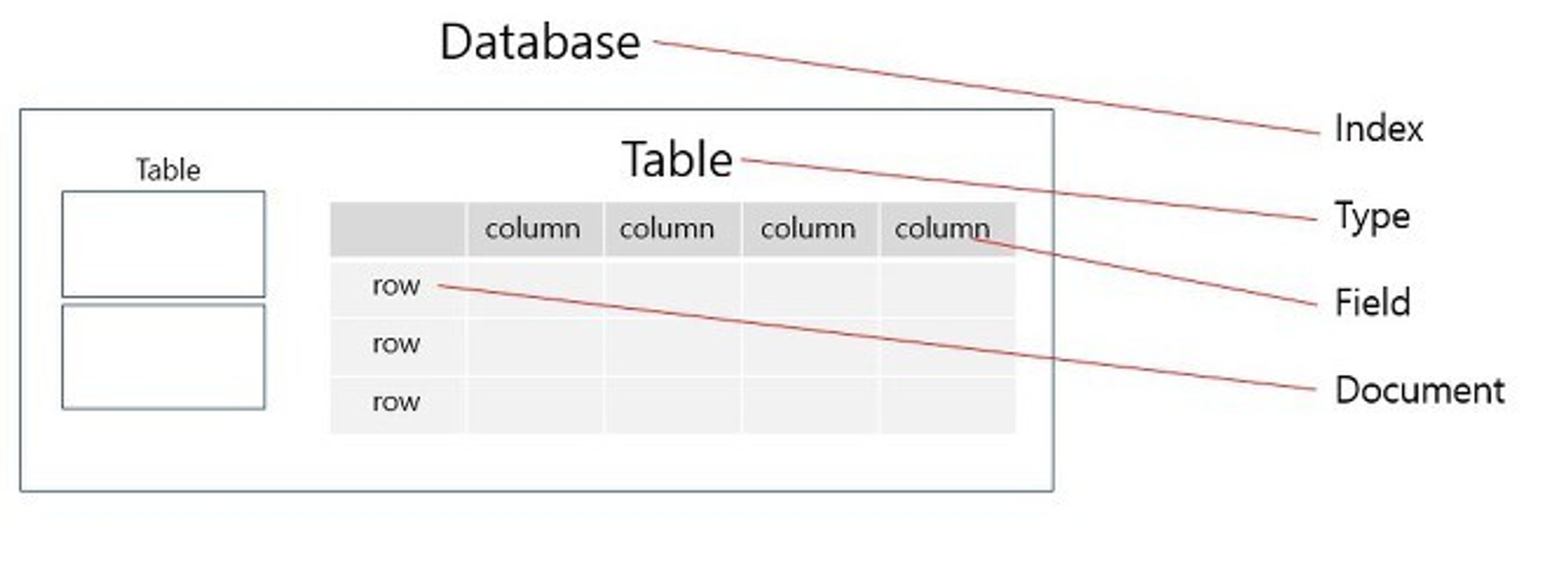
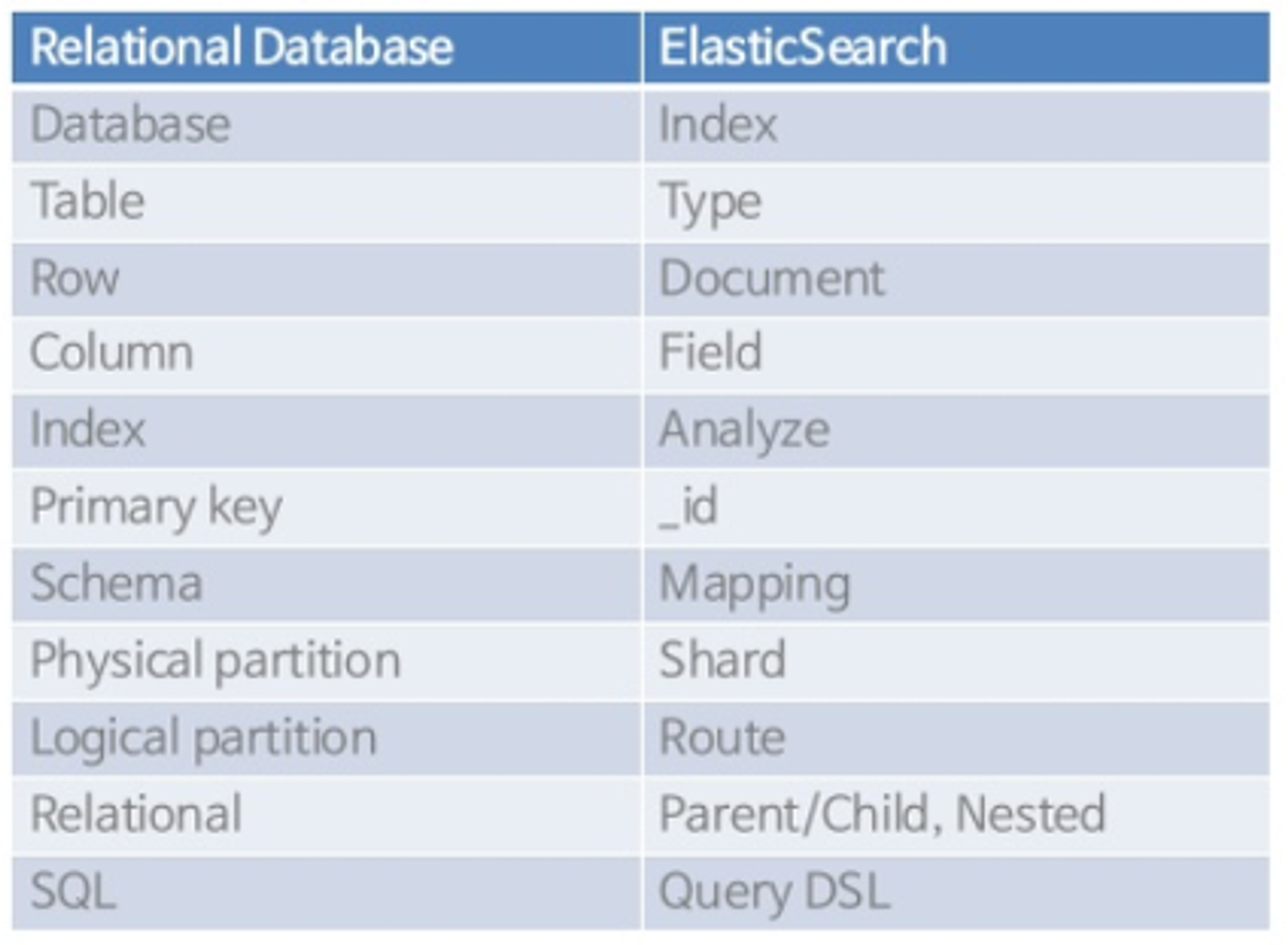
기존에 RDB를 많이 써 왔다면 Elasticsearch에서 사용하는 키워드와 매칭을 하기 쉽다. 다만, 인덱스와 타입에 대해 주의할 점이 있다.
한 인덱스 내의 멀티 타입이 가능한가?
위에서 인덱스는 RDB의 데이터베이스이고, 타입은 RDB의 테이블이라고 하였다. 하나의 데이터베이스에 여러 테이블을 가지듯이, Elasticsearch도 하나의 인덱스에 여러 타입을 가질 수 있다. 하지만 Elasticsearch 7.0 이상부터는 하나의 인덱스에는 하나의 타입만 가질 수 있도록 바뀌었다.
RDB의 테이블은 완전 개별적인 관계이기 때문에 각 테이블에 이름이 같은 컬럼이 있어도 문제가 없다. 가령 Twitter DB 안의 User Table, Tweet Table이 있고 각각의 테이블 안에 user_name이 있어도 상관 없다.
그런데, Elasticsearch에서 한 인덱스 내의 타입들은 내부적으로 같은 Lucene 필드를 사용한다. 쉽게 이야기하면, 위에서 예로 들었던 User 타입의 user_name 필드와 Tweet 타입의 user_name 필드는 동일한 필드에 저장되며 두 user_name 필드는 동일한 매핑(정의)을 가져야 한다.
따라서 타입이 다를지라도 동일한 이름을 가진 필드는 독립적이지 않으므로 여러 가지 문제가 발생할 수 있으므로 하나의 인덱스에는 하나의 타입만을 갖도록 수정되었다.
Elasticsearch의 구조
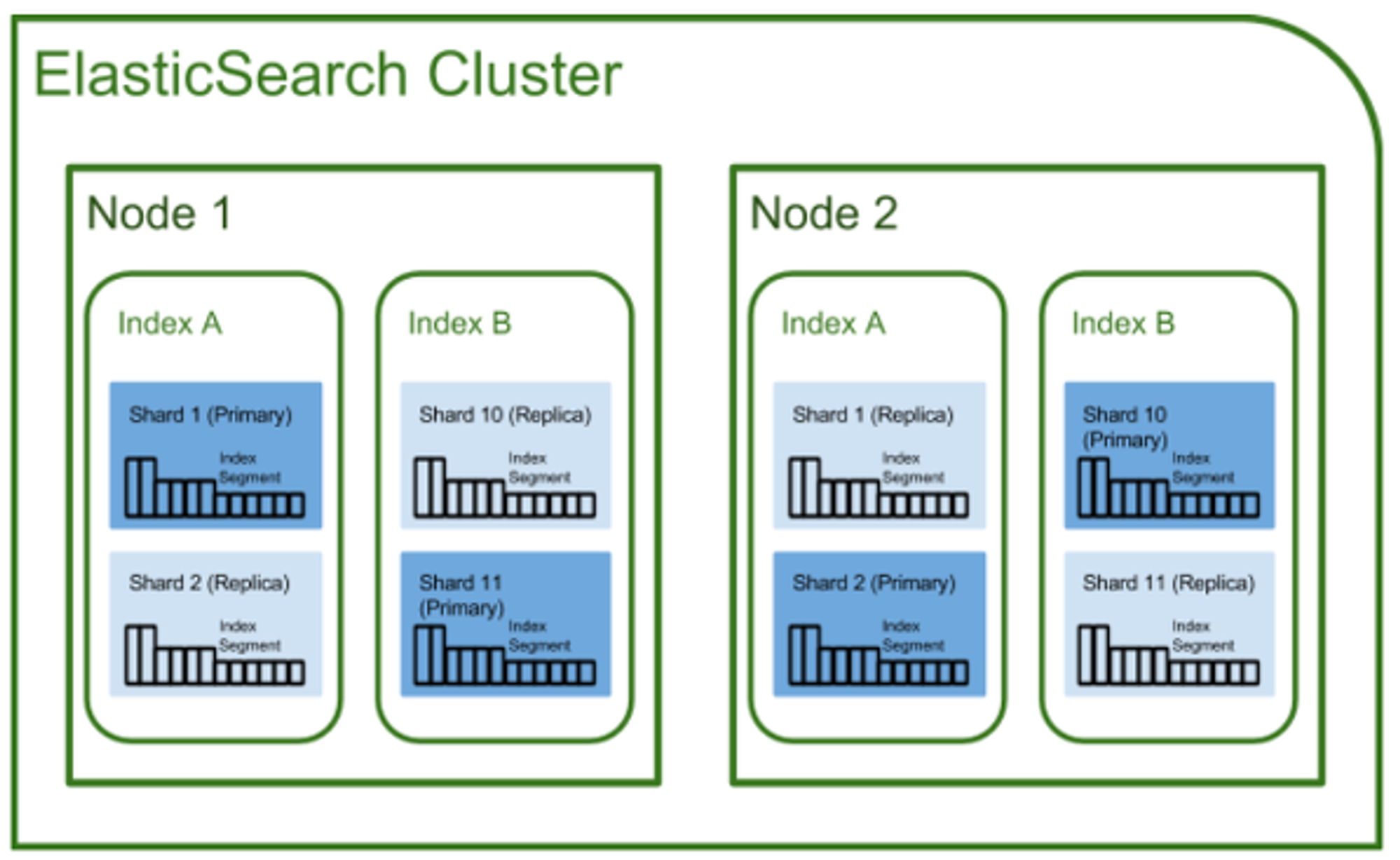
클러스터
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드의 집합이다. 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고 한 서버에 여러 개의 클러스터가 존재할 수 있다.
노드
노드는 클러스터에 포함된 단일 서버로서 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여한다. 노드는 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
Master-eligible Node
클러스터를 제어하는 마스터로 선택할 수 있는 노드이다. 마스터 노드가 하는 역할을 다음과 같다.
- 인덱스 생성, 삭제
- 클러스터 노드의 추적, 관리
- 데이터 입력 시 할당할 샤드 선택
Data Node
데이터(Document)가 저장되는 노드이며, 데이터가 분산 저장되는 물리적 공간인 샤드가 배치되는 노드이다. CRUD, 색인, 검색, 통계 등의 데이터 작업을 수행하므로 많은 리소스(CPU, 메모리 등)를 필요로 한다. 따라서 모니터링 작업을 해야 하고, 마스터 노드와는 분리해야 한다.
Ingest Node
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 한다.
Coordination Only Node
사용자의 요청을 받고 라운드 로빈 방식으로 분산을 하는 노드이다. 클러스터에 관련된 것은 마스터 노드로 넘기고, 데이터와 관련된 것은 데이터 노드로 넘긴다. 로드밸런싱 역할을 하는 노드라고 생각하면 된다.
인덱스 / 샤드 / 복제
인덱스 (Index)
앞서 이야기했듯, RDBMS에서 데이터베이스와 대응하는 개념이다.
샤드 (shard)
인덱스 내부에는 색인된 데이터들이 존재하는데, 이 데이터들은 하나로 뭉쳐서 존재하지 않고 물리적 공간에 여러 부분으로 나뉘어 존재한다. 이러한 부분을 샤드라고 한다. 즉, 스케일 아웃을 위해 하나의 인덱스를 여러 샤드로 쪼갰다고 생각하면 된다.

샤드는 프라이머리 샤드와 레플리카 샤드로 나뉜다.
- 프라이머리 샤드
- 데이터의 원본이다. Elasticsearch에서 데이터 업데이트 요청을 날리면 반드시 프라이머리 샤드에 요청하게 되고, 해당 내용은 레플리카 샤드에 복제된다. 검색 성능 향상을 위해 클러스터의 샤드 개수를 조정하기도 한다.
- 레플리카 샤드 (복제)
- 프라이머리 샤드의 복제본이다. 기존 원본 데이터가 무너졌을 때 그 대신 사용하면서 장애를 극복하는 역할을 수행한다. 기본적으로 원본인 프라이머리 샤드와 동일한 노드에 배정되지 않는다.

세그먼트
세그먼트란 Elasticsearch에서 문서의 빠른 검색을 위해 설계된 자료 구조이며, 샤드의 데이터를 가지고 있는 물리적인 파일이다. 각 샤드는 다수의 세그먼트로 구성되어 있으므로 검색 요청을 분산 처리하여 훨씬 효율적인 검색이 가능하다.
샤드에서 검색 시, 먼저 각 세그먼트를 검색하여 결과를 조합한 후 최종 결과를 해당 샤드의 결과로 반환하게 된다. 이때 세그먼트는 내부에 색인된 데이터가 역색인 구조로 저장되어 있으므로 검색 속도가 매우 빠르다.
그런데, 매 요청마다 새로운 세그먼트를 만들어 주면 엄청나게 많은 세그먼트가 생성될 것이고, 이로 인해 다른 요청에 지장이 생길 수 있다. 이를 방지하기 위해 인메모리 버퍼를 사용한다. 인메모리 버퍼에 쌓인 내용을 일정 시간이 지나거나 버퍼가 가득차면 flush를 취하고, flush 작업이 수행되면 시스템 캐시에 세그먼트가 생성된다. 이 시점부터 데이터가 비로소 검색이 가능해진다. 하지만 이 상태는 세그먼트가 시스템 캐시에 저장된 상태이지, 디스크에 저장된 상태는 아니다.
디스크에 쓰여지는 작업 역시 일정 시간이 지나면 commit을 통해서 물리적인 디스크에 세그먼트를 저장해 주고, 저장된 세그먼트는 시간이 지날수록 하나로 병합하는 과정을 수행한다. 병합을 통해 세그먼트를 하나로 줄여 주면, 검색할 세그먼트의 개수가 줄어들기 때문에 검색 성능이 향상된다.
정리

Elasticsearch의 장단점
장점
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안전성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행한다.
- SELECT = GET
- INSERT = PUT
- UPDATE = POST
- DELETE = DELETE
- Restful API를 사용한다는 것은 다양한 플랫폼에서 응용이 가능하다는 장점이 있다.
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행한다.
- 역색인
단점
- 실시간 처리가 불가능하다.
- elasticsearch는 인메모리 버퍼를 사용하므로 쓰기와 동시에 읽기 작업을 할 경우, 세그먼트가 생성되기 전까지는 해당 데이터를 검색할 수 없다.
- 트랜잭션을 지원하지 않는다.
- 분산 시스템 구성의 특징 때문에 시스템적으로 비용 소모가 큰 트랜잭션 및 롤백을 지원하지 않는다.
- 진정한 의미의 업데이트를 지원하지 않는다.
- 세그먼트에서 데이터가 삭제될 경우 Soft-Delete를 한다. (삭제 flag = true)
- 세그먼트에서 데이터가 수정될 경우 Soft-Delete를 하고, 수정된 데이터를 새로운 세그먼트로 생성한다.
- RDBMS의 Index와 유사한 동작.
출처
- https://victorydntmd.tistory.com/308
- https://twofootdog.tistory.com/53
- https://www.elastic.co/guide/kr/elasticsearch/reference/current/gs-basic-concepts.html
- https://velog.io/@jakeseo_me/엘라스틱서치-알아보기-2-DB만-있으면-되는데-왜-굳이-검색엔진
- https://wedul.site/497
- https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html
- https://ksk-developer.tistory.com/38
- https://m.blog.naver.com/whdgml1996/222082868722
예상 면접 질문 및 답변
Elasticsearch란?
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈 소스 분산 검색 엔진이다. Elasticsearch를 통해 루씬 라이브러리(Java에서 개발한 정보 검색용 라이브러리)를 단독으로 사용할 수 있으며, 방대한 양의 데이터를 신속하게(거의 실시간) 저장, 검색, 분석을 수행할 수 있다.
Elasticsearch는 언제 사용하는가?
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며, ELK(Elasticsearch / Logstash / Kibana) 스택으로 사용되기도 한다.
ELK를 왜 사용하는가?
주로 ELK는 로드밸런싱되어 있는 WAS의 흩어져 있는 로그를 한 곳으로 모으고, 원하는 데이터를 빠르게 검색한 뒤 시각화하여 모니터링하기 위해 사용한다
Elasticsearch의 구조를 설명하라.
Elasticsearch는 클러스터로 구성되며, 클러스터 안에 노드, 노드 안에 인덱스, 인덱스 안에 샤드, 샤드 안에 세그먼트로 구성된다.
각각의 특징은 본문을 참조할 것.
Elasticsearch는 왜 검색 속도가 빠른가?
역색인 자료 구조로 인해 빠르다.
Elasticsearch의 장점은?
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안전성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행한다.
- SELECT = GET
- INSERT = PUT
- UPDATE = POST
- DELETE = DELETE
- Restful API를 사용한다는 것은 다양한 플랫폼에서 응용이 가능하다는 장점이 있다.
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행한다.
- 역색인
Elasticsearch의 단점은?
- 실시간 처리가 불가능하다.
- elasticsearch는 인메모리 버퍼를 사용하므로 쓰기와 동시에 읽기 작업을 할 경우, 세그먼트가 생성되기 전까지는 해당 데이터를 검색할 수 없다.
- 트랜잭션을 지원하지 않는다.
- 분산 시스템 구성의 특징 때문에 시스템적으로 비용 소모가 큰 트랜잭션 및 롤백을 지원하지 않는다.
- 진정한 의미의 업데이트를 지원하지 않는다.
- 세그먼트에서 데이터가 삭제될 경우 Soft-Delete를 한다. (삭제 flag = true)
- 세그먼트에서 데이터가 수정될 경우 Soft-Delete를 하고, 수정된 데이터를 새로운 세그먼트로 생성한다.
- RDBMS의 Index와 유사한 동작.
Elasticsearch와 RDBMS의 차이는?
Elasticsearch는 Json 문서를 통해 검색을 수행하므로 스키마가 없지만, RDBMS는 엄격한 스키마가 존재한다.
Elasticsearch는 역색인 자료 구조로 검색을 수행하지만, RDBMS는 인덱스 자료 구조로 검색을 수행한다.
Elasticsearch는 저장소보다는 검색 엔진에 가깝다.
Elasticsearch와 NoSQL의 차이는?
Elasticsearch는 실시간 처리가 불가능하지만, NoSQL은 실시간 처리가 가능하다.
Elasticsearch는 역색인 자료 구조가 있지만, NoSQL은 없다.
Elasticsearch는 저장소보다는 검색 엔진에 가깝다.
'스터디 > CS 스터디' 카테고리의 다른 글
| [데이터베이스] 역색인이란? (2) | 2022.01.19 |
|---|---|
| [데이터 분산 처리] Kafka - What is Kafka (0) | 2022.01.16 |
| [데이터베이스] 스프링이 제공하는 트랜잭션의 핵심 기술 (0) | 2022.01.07 |
| [데이터베이스] 클러스터링 인덱스, 유니크 인덱스, 외래 키 (0) | 2022.01.04 |
| [데이터베이스] Connection Pool이란? (2) | 2022.01.04 |
댓글