

스터디/CS 스터디
[데이터베이스] 역색인이란?
cs-study에서 스터디를 진행하고 있습니다.
색인과 역색인

색인 (Index)
- 문서에서 키워드를 찾아 보기 쉽도록 정렬 및 나열한 목록이다.
- 책에서 맨 앞에 나와 있는 목차를 떠올리면 된다. (좌측 사진)
- 데이터베이스 관점으로 보자면 '추천사', '들어가며' 같은 목차의 제목은 PK와 같은 레코드를 대표하는 값을 의미하고, 몇번 페이지를 나타내는 것은 실제 데이터 레코드가 존재하는 물리적 주소로 이해하면 된다. 레코드에서 대표하는 값을 뽑기 때문에 문서에서 키워드를 뽑는 색인이라고 명명하는 것이다.
역색인 (Inverted Index)
- 키워드를 통해 문서를 찾아내는 방식이다.
- 책에서 맨 뒤에 나와 있는 찾아 보기를 떠올리면 된다. (우측 사진)
- 검색 성능이 매우 빠르다.
역색인은 왜 검색 성능이 빠를까?
- 검색은 대량의 문서 집합에서 "특정" 키워드가 포함된 문서를 찾아 내는 행위이다.
- 우선 색인을 사용하여 검색을 시도해 보자.
색인을 사용한 검색

- 우리가 ‘fox’라는 키워드를 통해 검색한다고 가정해 보자.
- 일반적으로 위의 테이블 데이터에서 한 줄씩 like ‘%fox’ 검색을 통해 데이터를 검색한다.
- 단순히 컬럼을 읽는 느낌이 아니라, 텍스트 하나 하나를 읽어야 한다는 사실을 명심해야 한다. 만약 Text가 1700쪽에 달하는 토비의 스프링이 저장되어 있다면, 검색을 위해 엄청난 양의 텍스트를 읽어야 한다.
- 전통적인 RDBMS에서는 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다.
역색인을 사용한 검색
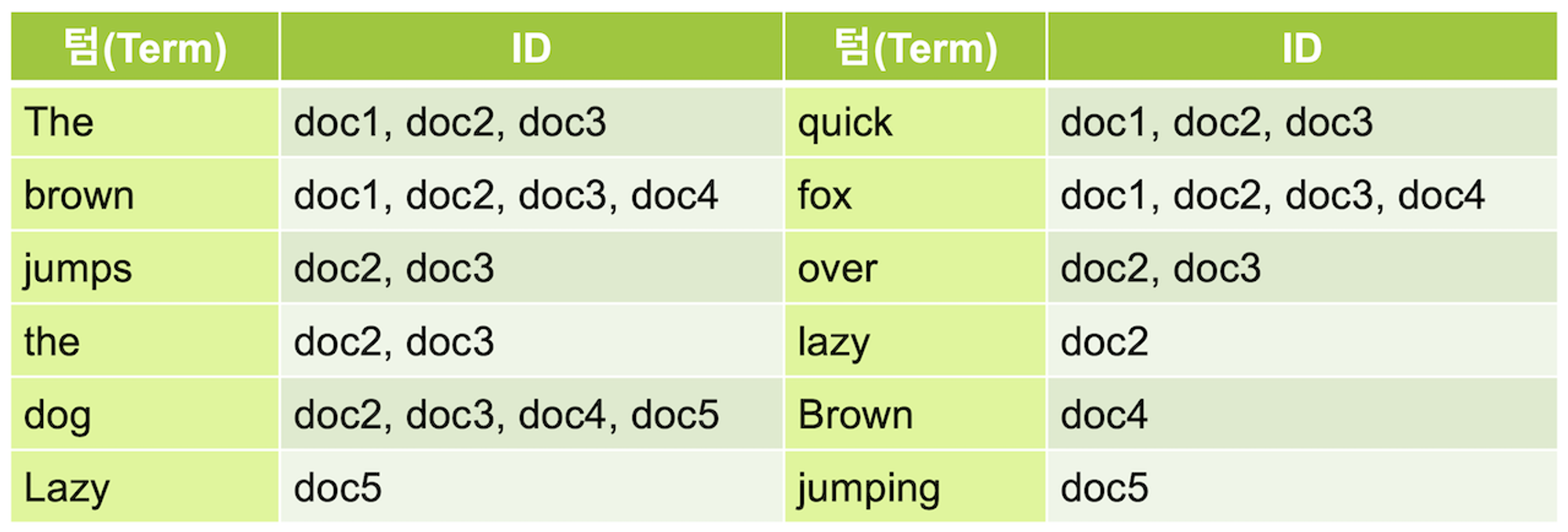
- 역색인은 앞서 말한 책의 맨 뒤에 있는 찾아 보기와 유사하다. (흔히 단어 사전이라고도 함)
- 역색인을 사용하는 검색 엔진에서는 추출된 각 키워드를 term이라고 부른다.
- 이렇게 역색인이 있으면, fox를 포함하고 있는 문서의 id를 바로 얻어 올 수 있다.
- 문서의 id는 PK, 물리적 주소 등에 해당한다.

- 역색인을 사용하면 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역색인이 가리키는 id의 배열 값이 추가되는 것이므로 큰 속도의 저하 없이 여전히 빠른 속도로 검색이 가능하다.
- 참고로 역색인을 데이터가 저장되는 과정에서 만들기 때문에 검색 엔진은 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현한다.
term은 어떻게 만들어질까?
- 위에서 검색 엔진에서 추출된 키워드를 term라고 하였다. 즉, 검색 엔진은 특정 문서에서 여러 키워드로 쪼갠다고 유추할 수 있다. 그렇다면, 문서를 여러 term으로 어떻게 나누는지 살펴 보자.
- 문서를 term으로 나누는 것을 텍스트 분석 혹은 처리한다고 한다.
- 두 가지 예문을 문서로 사용하겠다.
- The quick brown fox jumps over the lazy dog.
- Fast jumping rabbits.
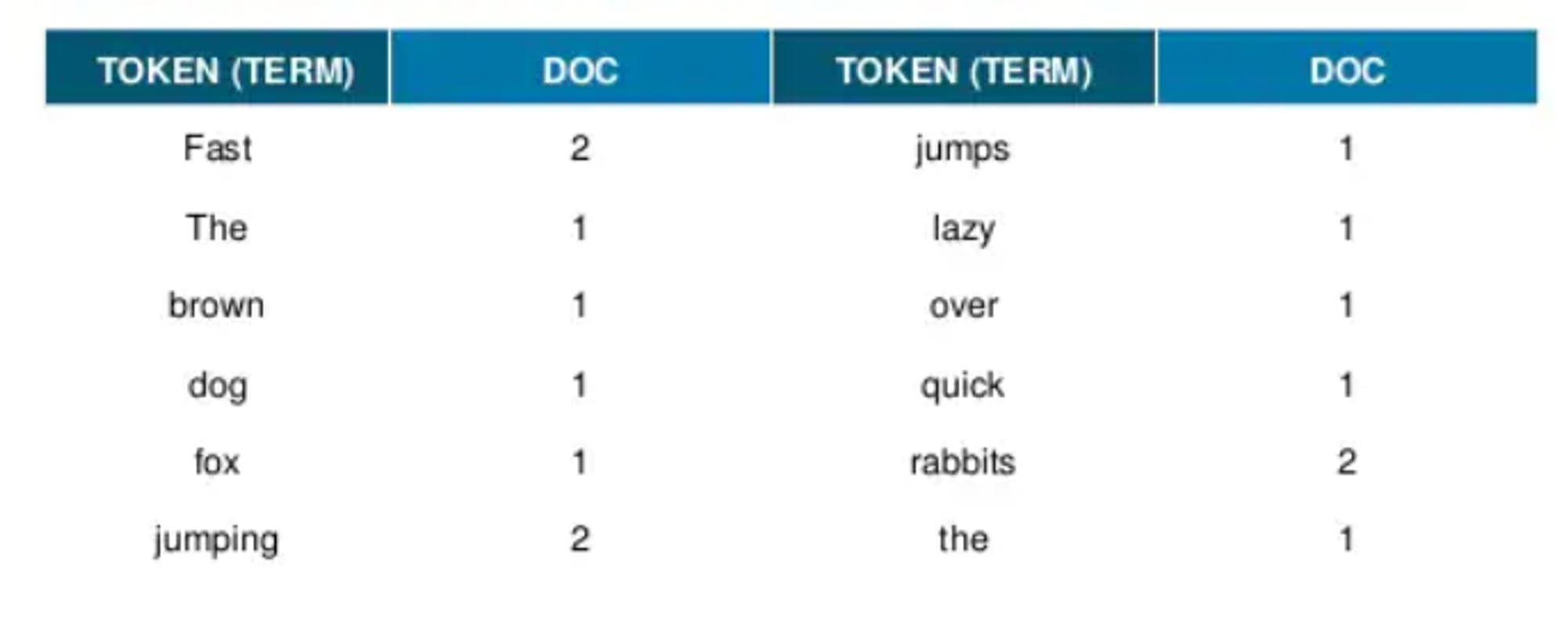
- 먼저 텍스트를 다 뜯어서 검색어 사전을 만든다. 띄어 쓰기 단위로 다 쪼개면 된다.
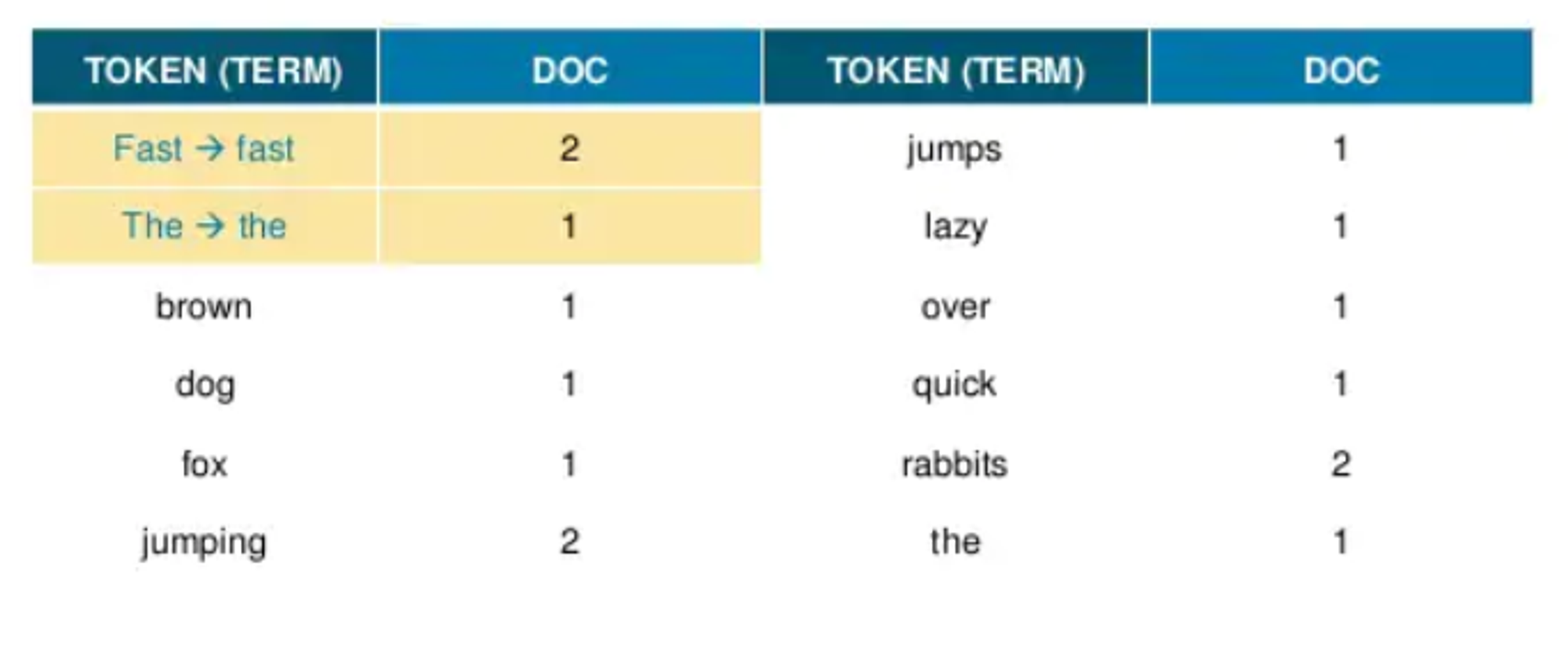
- 이때 대소문자를 소문자로 변환한다.
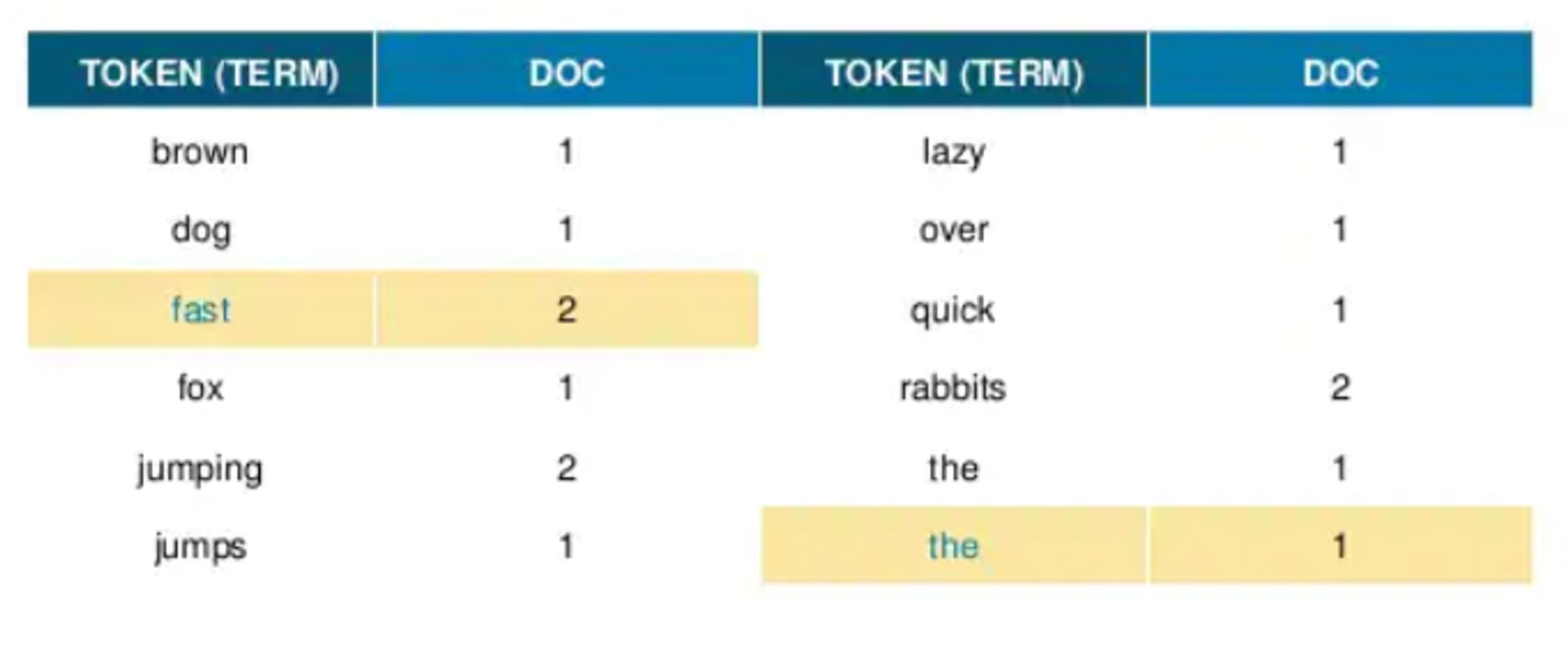
- 토큰을 ascii 순서로 재정렬한다.
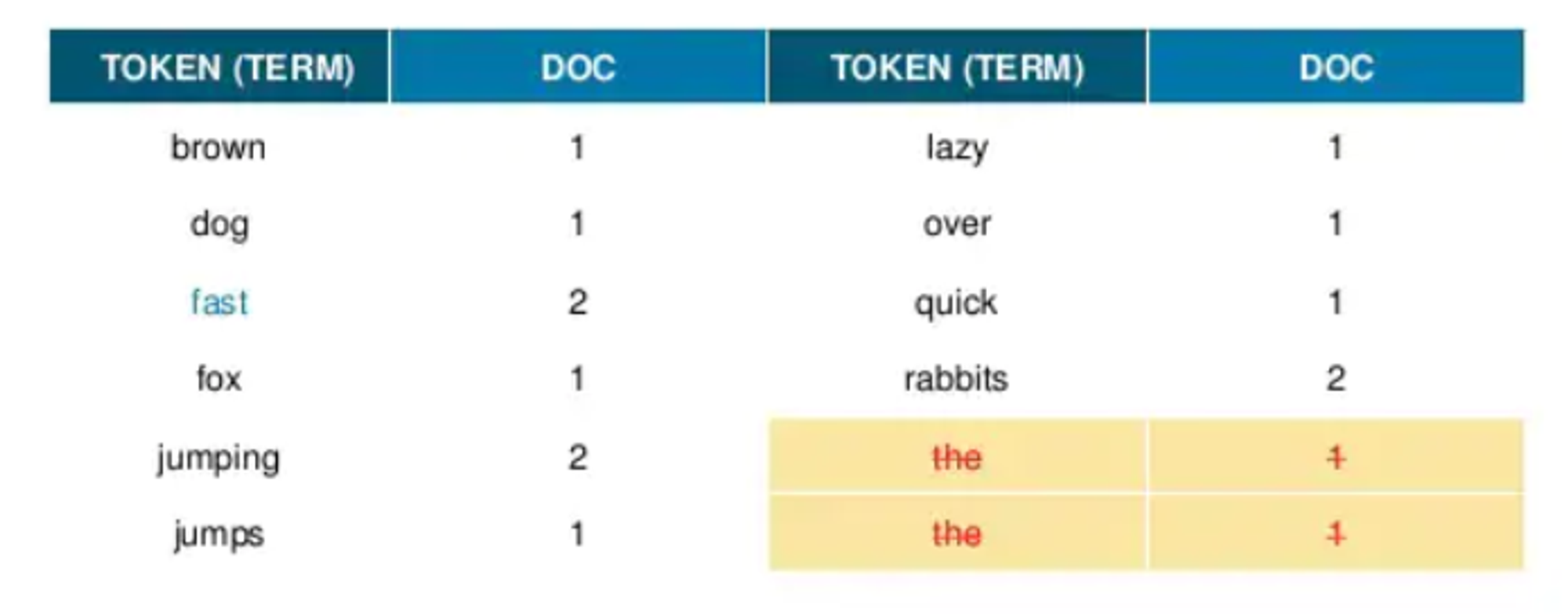
- 불용어를 제거한다.
- 검색어로서 가치가 없는 단어
- a, an, are, the, ...

- 형태소 분석 과정을 거친다.
- 보통 ~s, ~ing을 제거한다.
- 한글은 의미 분석을 해야 해서 좀 더 복잡하다.
- Elasticsearch에서는 한글 형태소 분석기로 nori를 주로 사용한다. (물론 Elasticsearch는 global하므로 한글 형태소 분석기를 수동으로 설치해야 함)
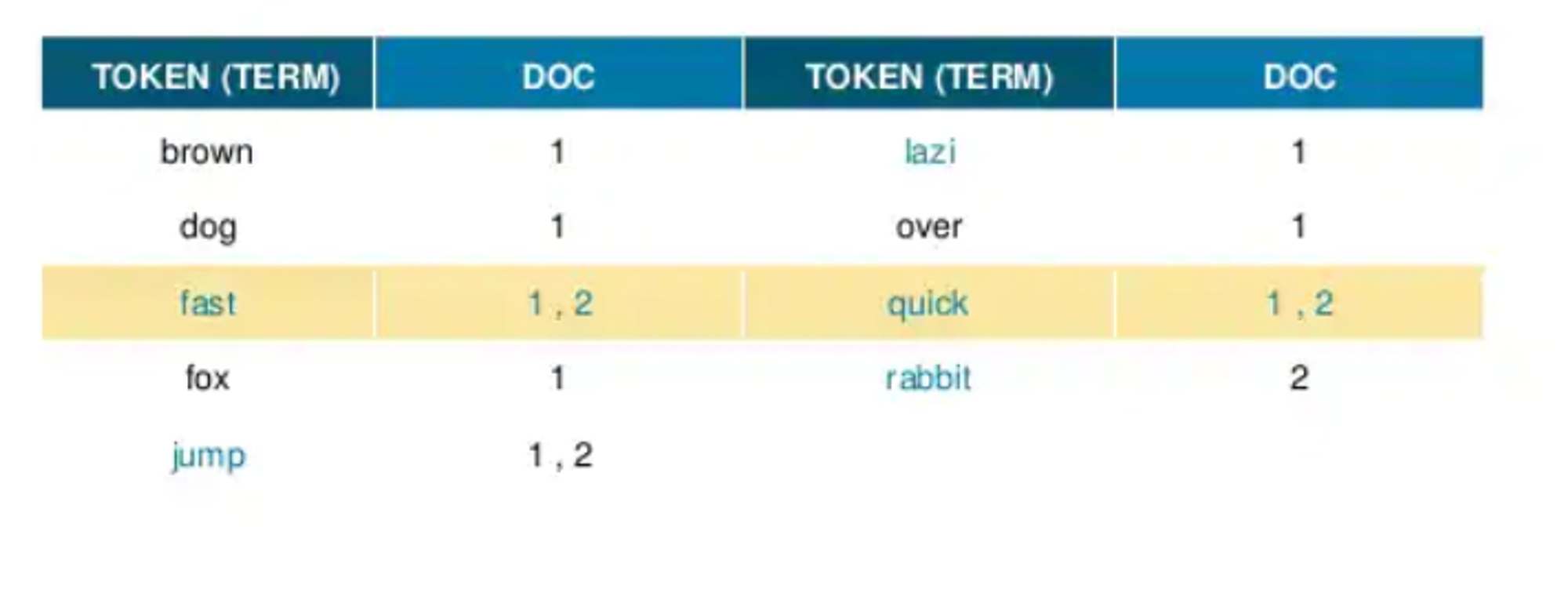
- 중복된 jump 토큰을 하나로 병합하고, 동의어를 처리한다.
- 이로써 역색인 구성이 완료된다.
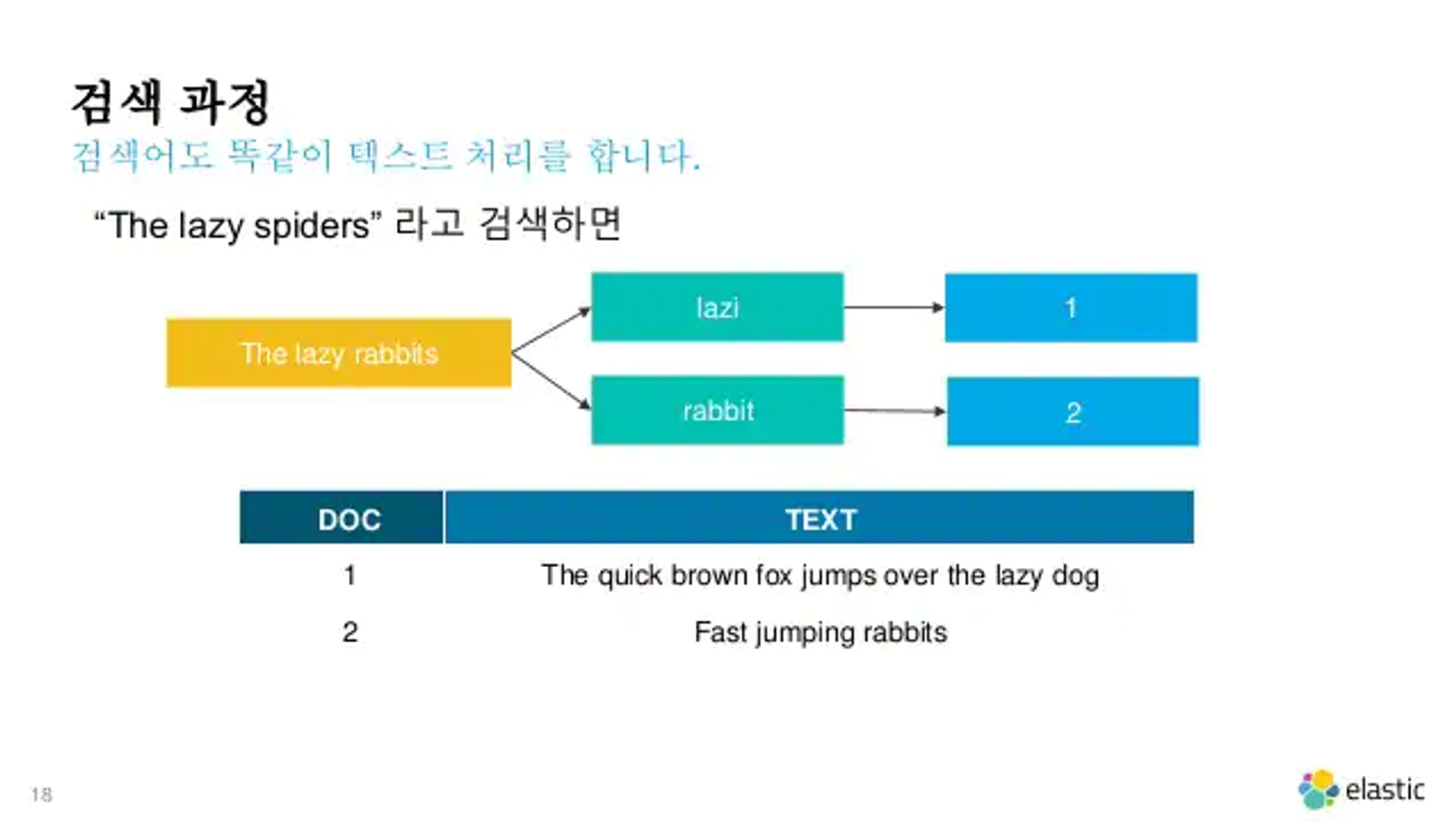
- 중요한 점은 검색 엔진에서 사용할 검색어도 위와 동일한 방식으로 텍스트 처리를 한다.
- “The lazy spiders”를 검색어로 사용하면, lazi와 rabbit으로 분리가 된다. 그리고 기존의 구성한 역색인을 활용하여 방금 분석한 term에 해당하는 문서의 ID를 알 수 있으므로 빠르게 ID에 맞는 실제 문서를 얻어올 수 있다.
기타 궁금증
Q. 검색어에 대해 텍스트 처리를 하고, 쪼개진 term의 개수가 많다면 매번 term을 찾기 위해 역색인을 O(N)만큼 순회하면 색인보다 성능이 떨어지는 것 아닌가?
루씬의 역색인 구조를 이용하는 Elasticsearch는 B-Tree와 유사하게 동작하는 Skip-Lists와 FST를 활용하여 O(log N)을 보장한다. 그래서 term의 개수가 많더라도 길이가 짧은 문서가 매우 적게 저장되어 있는 환경이 아닌 이상 역색인이 검색 성능이 좋다.
출처
- https://needjarvis.tistory.com/345
- https://the-dev.tistory.com/30
- https://woongsin94.tistory.com/345https://woongsin94.tistory.com/345
- https://stackoverflow.com/questions/2602253/how-does-lucene-index-documents
예상 면접 질문 및 답변
역색인이란?
- 키워드를 통해 문서를 찾아내는 방식이다.
- 책에서 맨 뒤에 나와 있는 찾아 보기를 떠올리면 된다.
색인을 사용한 검색은 왜 느린가?
- 전통적인 RDBMS에서는 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다. 특히 row 안의 내용이 길다면 하나의 row를 읽더라도 시간이 오래 걸린다.
역색인을 사용한 검색은 왜 빠른가?
- 역색인을 사용하면 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역색인이 가리키는 id의 배열 값이 추가되는 것이므로 큰 속도의 저하 없이 여전히 빠른 속도로 검색이 가능하다.
'스터디 > CS 스터디' 카테고리의 다른 글
| [데이터 분산 처리] MSA 아키텍처란? (0) | 2022.02.09 |
|---|---|
| [데이터베이스] Redis란? (1) | 2022.01.25 |
| [데이터 분산 처리] Kafka - What is Kafka (0) | 2022.01.16 |
| [데이터베이스] Elasticsearch란? (0) | 2022.01.12 |
| [데이터베이스] 스프링이 제공하는 트랜잭션의 핵심 기술 (0) | 2022.01.07 |
댓글