

[우아한 테크코스 3기] LEVEL 2 회고 - 배포 인프라 2단계 미션 (89일차)

안녕하세요? 제이온입니다.
어제에 이어서 배포 인프라 2단계 미션을 수행한 과정을 기록하려고 합니다.
배포 인프라 2단계 미션 - 애플리케이션 진단
가장 처음 한 일은 애플리케이션을 진단하는 것입니다.

어제 말씀드린 이 부분에서 웹 애플리케이션 링크를 들어가고 난 후, npm install 오류를 해결해 보았습니다.

여기서 frontend 디렉토리로 들어간 뒤, npm install을 실행하면 먼저 npm을 깔라고 알림이 뜰 것입니다. apt를 통해 npm을 깔고 npm install을 하면 뭔지 모를 에러가 쭈우욱 나옵니다.
이건 우분투의 npm 버전이 상당히 낮기 때문이라서 nvm을 통해 버전을 높여주면 됩니다. 이곳의 설명에 따라 nvm을 설치하고, 적절한 버전으로 깔면 문제 없이 npm install이 가능해 집니다.
이후 시키는 대로 webpack을 & 키워드를 통해 백그라운드로 실행하고, 애플리케이션을 구동하면 끝입니다. 참고로 "Started SubwayApplication in 3.837 seconds (JVM running for 4.153)" 메시지 이후에도 빌드가 끝나지 않고 80퍼센트에서 멈춰있을 수 있는데, 그냥 컨트롤 Z로 빠져 나오면 됩니다.
이제 차례대로 curl 명령어를 통해 웹 요청을 보내겠습니다.

[ ], ok, ok라는 응답이 오는 것을 확인할 수 있습니다. 왜 이렇게 응답이 날아오는지는 api 설계가 어떻게 되어있는지 보면 됩니다.
@RestController
@RequestMapping("/lines")
public class LineController {
private final LineService lineService;
public LineController(final LineService lineService) {
this.lineService = lineService;
}
@PostMapping
public ResponseEntity createLine(@RequestBody LineRequest lineRequest) {
LineResponse line = lineService.saveLine(lineRequest);
return ResponseEntity.created(URI.create("/lines/" + line.getId())).body(line);
}
@GetMapping
public ResponseEntity<List<LineResponse>> findAllLines() {
return ResponseEntity.ok(lineService.findLineResponses());
}
@GetMapping("/{id}")
public ResponseEntity<LineResponse> findLineById(@PathVariable Long id) {
return ResponseEntity.ok(lineService.findLineResponseById(id));
}
@PutMapping("/{id}")
public ResponseEntity updateLine(@PathVariable Long id, @RequestBody LineRequest lineUpdateRequest) {
lineService.updateLine(id, lineUpdateRequest);
return ResponseEntity.ok().build();
}
@DeleteMapping("/{id}")
public ResponseEntity deleteLine(@PathVariable Long id) {
lineService.deleteLineById(id);
return ResponseEntity.noContent().build();
}
@PostMapping("/{lineId}/sections")
public ResponseEntity addLineStation(@PathVariable Long lineId, @RequestBody SectionRequest sectionRequest) {
lineService.addLineStation(lineId, sectionRequest);
return ResponseEntity.ok().build();
}
@DeleteMapping("/{lineId}/sections")
public ResponseEntity removeLineStation(@PathVariable Long lineId, @RequestParam Long stationId) {
lineService.removeLineStation(lineId, stationId);
return ResponseEntity.ok().build();
}
@ExceptionHandler(DataIntegrityViolationException.class)
public ResponseEntity handleIllegalArgsException(DataIntegrityViolationException e) {
return ResponseEntity.badRequest().build();
}
static final Object left = new Object();
static final Object right = new Object();
@GetMapping("/lock-left")
public String findLockLeft() throws InterruptedException {
synchronized (left) {
Thread.sleep(5000);
synchronized (right) {
System.out.println("left");
}
}
return "ok";
}
@GetMapping("/lock-right")
public String findLockRight() throws InterruptedException {
synchronized (right) {
Thread.sleep(5000);
synchronized (left) {
System.out.println("right");
}
}
return "ok";
}
@GetMapping("/tan")
public String generateStreams() {
double value = 0;
IntStream.of(100).parallel().map(extracted(value));
extracted(value);
return "ok";
}
private IntUnaryOperator extracted(double value) {
while (value >= 0) {
value = Math.tan(value);
}
return null;
}
}
Spring의 컨트롤러 단의 코드를 보니까, GET 메소드를 찾을 수 있었습니다. "/lines" Get 요청의 경우, findAllLines() 메소드를 나머지 "/lines/lock-left"나 "/lines/lock-right" Get 요청의 경우, findLockLeft()나 findLockRight() 메소드를 호출하는 것으로 추정됩니다. 참고로 "/lines/tan"은 상응하는 api가 있으나, 무슨 이유인지 아무리 기다려도 통신 결과가 안 나왔습니다.

제 생각에는 1부터 100까지의 요소에 대해 탄젠트 연산을 수행하는 것 같은데, 이상하게도 10분 기다려도 응답이 오지 않았습니다. 그래서 코드를 찬찬히 보았습니다.
처음에 extracted() 메소드의 인자로 0이 들어가는데, 탄젠트 0은 0이므로 while문을 벗어나지 못하고 무한루프를 도는 것입니다! 그래서 "/lines/tan"은 영원히 "ok"라는 응답을 받지 못하는 것이죠.
그리고 arthas를 통해 CPU를 확인해 보니까 다음과 같았습니다.

"lines/tan"은 무한루프를 돌기 때문에 저렇게 CPU 사용량이 확 치솟은 것을 확인할 수 있습니다.

CPU 사용량 외에도 tt 명령어를 통해 특정 메소드의 정보를 얻어올 수 있습니다. 위 표에 나오는 명령어의 의미는 아래와 같습니다.

요약하자면 어떠한 클래스에 있는 메소드가 호출되는데 걸리는 시간이 얼마나 걸렸고, 언제 호출되었고, 정상 종료되었는지 등에 대한 정보를 알아낼 수 있습니다. tt 명령어에 대한 자세한 내용은 이곳에서 참고하시길 바랍니다. 강의 자료에는 아래 명령어를 예시로 들었습니다.
tt -t nextstep.subway.member.ui.MemberController findMemberOfMine
findMemberOfMine() 메소드의 코드도 한 번 봅시다.
@GetMapping("/members/me")
public ResponseEntity<MemberResponse> findMemberOfMine(@AuthenticationPrincipal LoginMember loginMember) {
MemberResponse member = memberService.findMember(loginMember.getId());
return ResponseEntity.ok().body(member);
}
해당 메소드는 MemberController 내의 존재합니다. 그리고 Get 방식으로 "/members/me"일 때 호출되는 것을 알 수 있죠. 이것은 로그인과 관련된 것으로 판단되며, 브라우저 내에 있는 로그인과 관련된 이벤트를 발생시켜 보았습니다.

우측 상단에 있는 로그인 버튼을 눌러서 회원 가입을 해 보았습니다. 회원가입 후 로그인을 할 때 해당 메소드가 호출되지 않을까 예상합니다.

저의 생각대로 회원 가입 이후 로그인할 때 findMemberOfMine()이 호출되었습니다. 다만, 로그인 실패할 때는 호출이 되지 않았습니다.
이번에는 trace 명령어를 입력해 보겠습니다. 마찬가지로 실행해 놓고, 로그인을 해 보았습니다.

아까보다 통신 과정이 더 자세히 나오는 것을 알 수 있습니다. trace 명령어의 자세한 설명은 이곳을 참고하시길 바랍니다.
배포 인프라 2단계 미션 - 파일 전송

서비스 서버에서 Bastion 서버로 파일을 전송하고, Bastion 서버에서 로컬에 파일 전송하는 방법입니다. 처음에는 rsync 명령어를 통해 서비스 서버에서 Bastion 서버로 파일을 전송합니다. 자세한 rsync 명령어는 해당 링크에서 확인하시길 바랍니다. 참고로, 위의 첫 번째 명령어는 Bastion 서버 입장에서 서비스 서버의 파일을 내려받는 것입니다. 반대로 하려면 "rsync -avzh [보낼 경로] [원격대상경로]"를 입력하면 됩니다.
그런데, 저는 bastion에서 서비스로 파일 전송이나 내려받는건 가능해도 서비스에서 bastion으로 파일을 전송하거나 내려받는건 불가능했습니다. 이에 대해서 슬랙 질문방에 질문을 남겼더니, 손너잘이 또 답변을 잘해주셨습니다.

요약하자면, 처음에 bastion 서버의 공개키를 서비스 서버에서 등록했던 것처럼 서비스 서버의 공개키를 bastion 서버에 등록하면 됩니다. 저는 service 서버에 있는 logs 디렉토리를 bastion 서버로 한 번 전송해 보겠습니다.

이렇게 서비스 서버에서 bastion 서버로 파일을 전송했습니다. 정말로 logs 디렉토리를 받았는지 확인해 봅시다.

잘 받은 것을 확인할 수 있습니다.
이제, bastion 서버에서 로컬로 logs 디렉토리 내에 존재하는 arthas.log 파일 하나만 전송해 보겠습니다. 이때는 scp 명령어를 사용합니다. -i 옵션을 주면 pem key를 통해 전송이 가능합니다. 저는 윈도우이므로 윈도우 기준으로 설명하겠습니다.
먼저, ppk 형태의 파일을 pem 파일로 변환해 줍니다. 이것은 이 링크를 확인하여 변환하시길 바랍니다. 그리고 cmd를 열어서 아래 명령어를 입력합니다.
scp -i [pem 키 파일 경로] ubuntu@[원격 IPv4 퍼블릭 IP]:[bastion 서버에서 보낼 주소] [로컬로 받을 주소]
다만, 이때 권한 관련하여 오류가 발생할 수 있는데 원인은 2가지입니다. 첫 번째는 선택적 기능 관리 내의 OpenSSH 클라이언트가 설치되어 있지 않은 경우입니다.

이렇게 윈도우의 경우, OpenSSH 클라이언트가 있어야 권한 오류가 생기지 않습니다.
두 번째는 pem 파일을 사용하는 권한을 파일 소유자한테만 주어야 합니다.
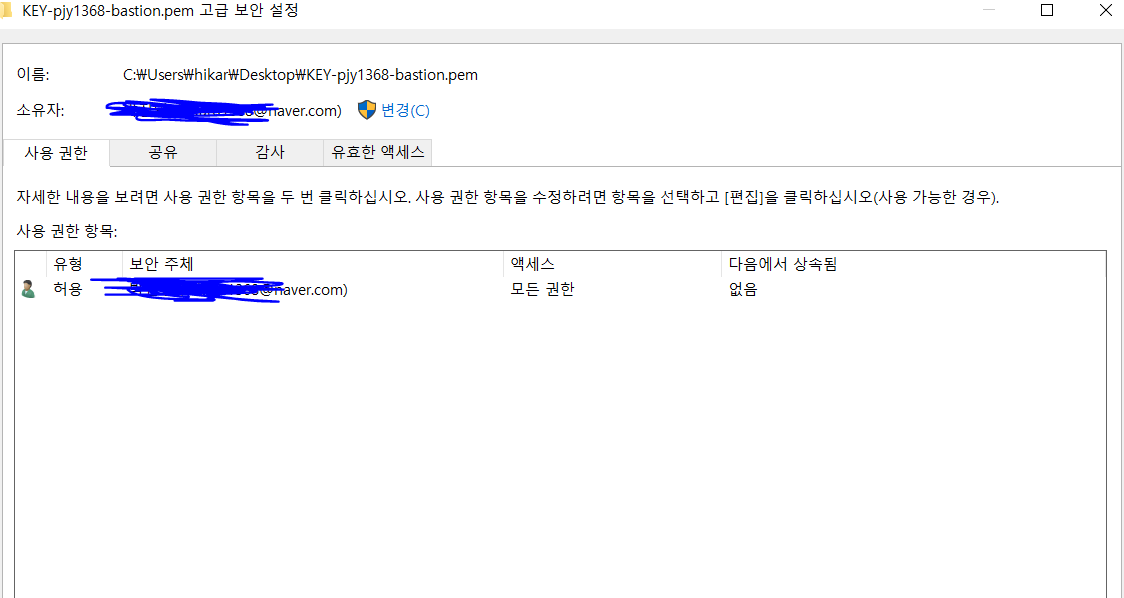
위와 같이 사용 권한 항목에는 소유자와 동일한 사용자만 있어야 합니다. 저는 이 외의 다른 3가지 사용자가 있어서 too open 이라는 오류가 발생했었습니다.
위 2가지 문제를 해결하였다면, 정상적으로 bastion 서버에서 arthas.log라는 파일을 내려받을 수 있습니다.

이렇게 cmd에서 명령어를 입력하고, 바탕화면을 확인해 보겠습니다.

정상적으로 arthas.log가 다운된 것을 확인할 수 있습니다.
배포 인프라 2단계 미션 - 로깅
해당 링크에서 clone하여 시작했습니다. 사실, 이미 예제 코드에서 xml 파일이나 여러 가지 로깅을 위한 작업이 모두 되어 있어서 단순히 실행만 해도 로깅이 되는 모습을 확인할 수 있습니다. 다만, "feat/logging" 브랜치로 checkout을 반드시 해야 합니다.

이렇게 curl 통신 요청해 보니까 로깅 파일을 확인하라는 문구가 보입니다. 해당 파일은 "/java-deploy/log"에서 확인할 수 있습니다.

file.log는 위와 같이 로그가 찍힙니다. 로그가 이렇게 찍히는 이유는 file_appender.xml을 보면 알 수 있습니다.

자세한 코드는 모르겠으나 Pattern 태그 내용을 보니까 이 형식대로 로그가 찍힌 것으로 판단됩니다.

이것은 json.log 파일입니다. 보기 좀 힘들지만, 대략적으로 여러 가지 정보가 담긴 json 파일임을 알 수 있습니다.

이것은 json-appender 파일입니다. 어디 부분에서 json 형식으로 파싱해 주는지는 잘 모르겠으나 fieldNames 태그 안에 내용 포맷대로 로그 파일에 기록되는 것으로 판단됩니다.
다음으로는 Nginx Log입니다.
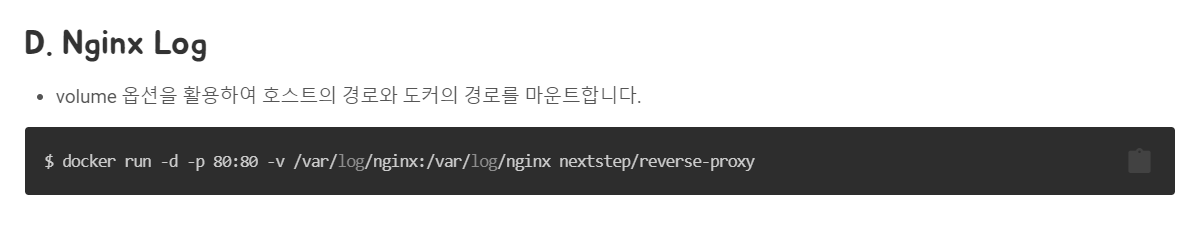
제가 이거 그대로 실행해보니까 오류가 나서 슬랙 질문방에 질문을 남겼습니다. 감사하게도 손너잘이 답변을 상세하게 달아주셨습니다.

결국 nextstep 레포지가 도커 허브란 곳에 존재하지 않는 것이 오류의 원인이었고, 마지막 파라미터를 nginx:latest로 수정하니까 nginx 디렉토리가 /var/log 안에 생기게 되었습니다. 그리고 그 안에는 access.log와 error.log가 존재하는 것을 확인하였습니다.
마지막으로 cAdvisor 사용입니다. 먼저, 아래 명령어를 복붙해 줍니다.
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
그러면 자동으로 해당 컨테이너가 실행이 되고, IPv4 퍼블릭 주소에 8080 포트를 붙여서 브라우저에 접속을 해 봅니다.

/docker를 눌러보면 현재 실행중인 컨테이너를 확인할 수도 있고, 여러 가지 CPU/메모리 사용량, 네트워크 트래픽 사용량 등 다양한 정보를 모니터링할 수 있습니다.
이후에 사용을 그만하고 싶다면 docker ps를 통해 해당 컨테이너의 ID를 파악한 다음 sudo docker stop <컨테이너 ID> 명령어를 통해 cAdvisor를 종료할 수 있습니다.
배포 인프라 2단계 미션 - CloudWatch
CloudWatch를 통해 로그와 매트릭스를 수집할 수 있습니다.

이건 시키는 대로 IAM role 설정을 합니다. 이후에 아래와 같은 명령어를 따라 칩니다.
$ curl https://s3.amazonaws.com/aws-cloudwatch/downloads/latest/awslogs-agent-setup.py -O
$ sudo python ./awslogs-agent-setup.py --region ap-northeast-2
파이썬이 안 깔려있다면 sudo apt install 명령어로 python을 깔고 다시 진행합니다.

위와 같이 설치창이 뜰텐데, 사실 앵간한 건 엔터치고 넘어가면 됩니다. Key ID 옆에 [***ecd9] 부분은 제가 이걸 입력해야 하는 줄 알고 삽질한건데 그냥 엔터쳐서 넘어가도 무방합니다.

여기까지 일단 엔터를 쳐 줍니다.

그리고 위와 같이 세 가지 로그 파일을 만들어야 합니다. 이때 로그그룹_이름은 깃허브 ID-sys, 깃허브 ID-access, 깃허브 ID-error 형태로 포맷을 지으라고 명시되어있습니다.

이런 방식으로 위에 제시된 포맷대로 파일을 만들어 줍니다.

이렇게 access.log를 만듭니다.

마찬가지로 error.log도 생성하면 끝입니다. 이제 sudo service awslogs restart를 한 이후에 새롭게 생성된 awslogs.conf를 확인해 봅니다.

이렇게 잘 되어 있는데, {instance_id}를 본인의 AWS EC2 인스턴스 ID로 바꿔야하나 궁금해서 씨유한테 질문하였더니 그럴 필요는 없다고 합니다.
이제 EC2 매트릭스를 수집하기 위하여 아래 명령어를 입력합니다.
$ wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
$ sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
그리고 아래 json 파일을 vi로 열어서 내용을 붙여 줍니다.
# /opt/aws/amazon-cloudwatch-agent/bin/config.json
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "root"
},
"metrics": {
"metrics_collected": {
"disk": {
"measurement": [
"used_percent",
"used",
"total"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent",
"mem_total",
"mem_used"
],
"metrics_collection_interval": 60
}
}
}
}
그리고 아래 명령어를 입력했을 때 동일한 status가 나와야 합니다.
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status
{
"status": "running",
"starttime": "2021-03-20T15:12:07+00:00",
"configstatus": "configured",
"cwoc_status": "stopped",
"cwoc_starttime": "",
"cwoc_configstatus": "not configured",
"version": "1.247347.5b250583"
}
그 다음은 수집할 데이터를 대시보드화해야합니다.

이렇게 다양한 지표에 대해서 그래프로 만들면 됩니다. 대시보드는 이곳에서 생성이 가능합니다.
대시보드 생성을 누르고 행, 지표를 선택한 후에 다음과 같이 본인의 EC2 인스턴스 ID를 입력합니다.

다만, 여기에는 mem_used_percent나 disk_used와 같은 지표는 없는데, 이건 그냥 검색을 해 봅니다.
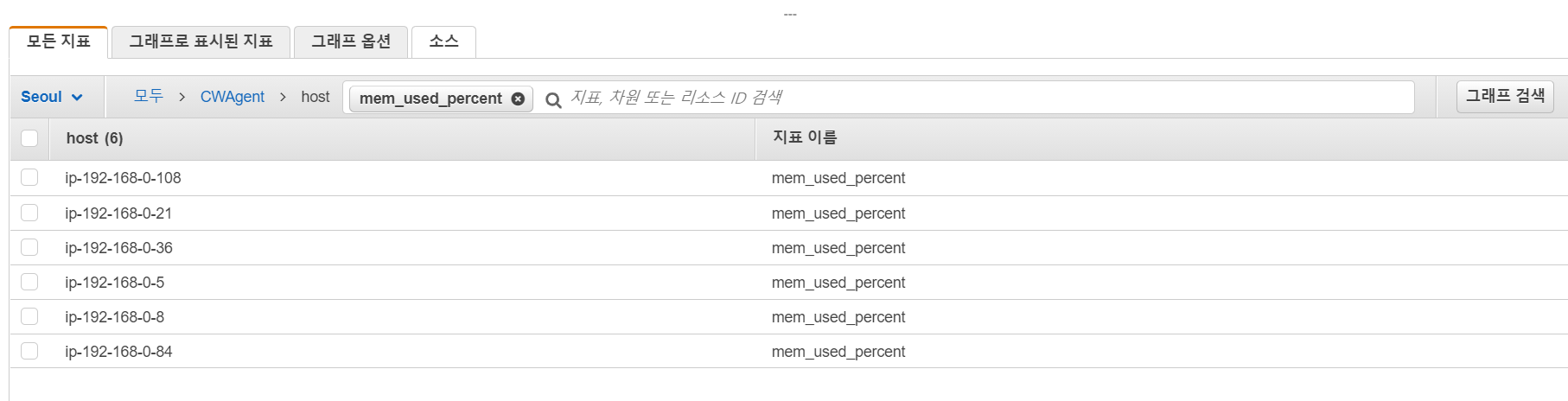
자신의 내부 IpV4 IP와 일치하는 것을 택하면 됩니다. 참고로 disk_used_percent와 같은 지표는 device가 xvda1인 것을 선택합니다.

여기까지 선택했으면 대시보드는 다음과 같이 잘 만들어졌을 것입니다.

배포 인프라 2단계 미션 - Spring Actuator Metric 수집
마지막으로 Spring boot를 이용한 모니터링입니다. 먼저, 아래의 의존성을 추가합니다.
dependencies {
implementation("org.springframework.boot:spring-boot-starter-actuator")
implementation("org.springframework.cloud:spring-cloud-starter-aws:2.2.1.RELEASE")
implementation("io.micrometer:micrometer-registry-cloudwatch")
}
그리고 application.properties 또는 yml 파일에 아래 내용을 기입합니다.
cloud.aws.stack.auto=false # 로컬에서 실행시 AWS stack autoconfiguration 수행과정에서 발생하는 에러 방지
cloud.aws.region.static=ap-northeast-2
management.metrics.export.cloudwatch.namespace= # 해당 namespace로 Cloudwatch 메트릭을 조회 가능
management.metrics.export.cloudwatch.batch-size=20
management.endpoints.web.exposure.include=*
그리고 아무 애플리케이션이나 실행합니다. 저는 이전에 배포했던 체스에 적용했습니다. 우선, "/actuator"를 검색해 봅니다.

그럼 위와 같이 actuator이 제공하는 다양한 endpoint를 볼 수 있습니다. 이제 여기서 다양한 endpoint를 넣어 보면서 데이터를 확인하면 됩니다. 이번 소제목이 매트릭스이므로 metrics를 입력해 보겠습니다.

뭔가 주루룩 뜨긴하는데.. 아는 분은 댓글 부탁드립니다.
정리
금방 끝날 줄 알았던 2단계 미션이.. 하다보니까 굉장히 오랜 시간이 걸렸던 것 같습니다. 아무래도 리눅스를 다루는 것이 어색하고 네트워크 및 시스템 쪽 지식이 빈약해서 꽤 힘들었습니다. 그래도 요구 사항 대부분을 지키면서 미션을 잘 수행한 것 같아서 다행입니다 ㅎㅎ..
그리고 오늘 미션을 수행하는 데 있어서 우기가 정말 많은 도움을 주었습니다.
'각종 후기 > 우아한테크코스' 카테고리의 다른 글
| [우아한 테크코스 3기] LEVEL 2 회고 (92일차) (4) | 2021.05.04 |
|---|---|
| [우아한 테크코스 3기] LEVEL 2 회고 (91일차) (4) | 2021.05.03 |
| [우아한 테크코스 3기] LEVEL 2 회고 (88일차) (2) | 2021.04.30 |
| [우아한 테크코스 3기] LEVEL 2 회고 (87일차) (0) | 2021.04.29 |
| [우아한 테크코스 3기] LEVEL 2 회고 (86일차) (4) | 2021.04.28 |
댓글