

[이펙티브 자바] 아이템 6. 불필요한 객체 생성을 피하라
effective-java에서 스터디를 진행하고 있습니다.
불필요한 객체를 생성하는 경우
new String() 사용
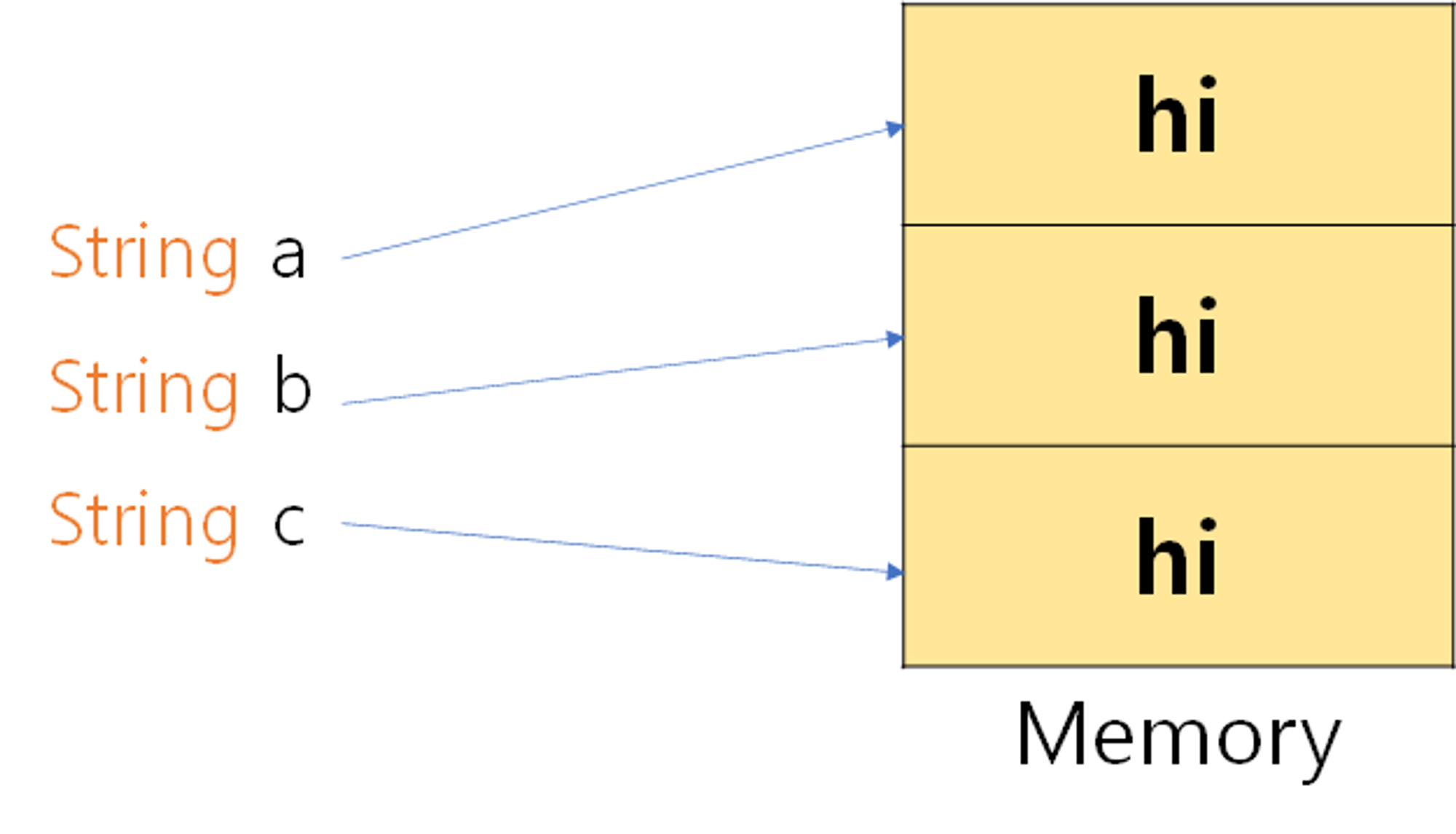
String a = new String("hi");
String b = new String("hi");
String c = new String("hi");
문자열 a, b, c는 모두 “hi”라는 문자열을 갖게 된다. 하지만, 이 세 문자열이 참조하는 주소는 모두 다르기 때문에 동일한 데이터에 대해 서로 다른 메모리를 할당한다는 낭비가 발생한다.
그래서 문자열을 선언할 때는 new 키워드를 쓸 것이 아니라 리터럴로 선언해야 한다.
String a = "hi";
String b = "hi";
String c = "hi";
위 소스 코드는 하나의 인스턴스만 사용한다. 더 나아가 이 방식을 사용한다면 같은 JVM 안에서 “hi” 문자열 리터럴을 사용하는 모든 코드가 같은 객체를 재사용함을 보장한다. 이것은 Java 상수 풀의 특징 때문에 그렇다.
new Boolean() 사용
Boolean b = new Boolean("true");
위 코드는 문자열을 매개변수로 받는 생성자를 통해 Boolean 인스턴스를 만들고 있다. Boolean은 true 혹은 false만 존재하는데, 매번 인스턴스를 만드는 것은 메모리 낭비가 된다. 따라서 정적 팩터리 메서드인 Boolean.valueOf() 를 사용하는 것이 좋다.
Boolean b = Boolean.valueOf("true");
String.matches() 사용
생성 비용이 크면 캐싱하여 재사용하는 것이 좋지만, 항상 우리가 만드는 객체의 비용을 알 수는 없다. 예를 들어 주어진 문자열이 유효한 로마 숫자인지 확인하는 메서드를 작성하고 싶다면, 다음과 같이 정규 표현식을 활용하는 것이 가장 쉽다.
public static boolean isRomanNumeral(String s) {
return s.matches("^(?=.)M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}
하지만 String.matches() 는 성능적으로 문제가 있는 메서드이다. 이 메서드가 내부에서 만드는 정규 표현식용 Pattern 인스턴스는, 한 번 쓰고 버려져서 곧바로 가비지 컬렉션 대상이 되는데, 해당 정규 표현식이 반복해서 사용되는 빈도가 높아질수록 동일한 Pattern 인스턴스가 생성되고 버려지는 비용이 커진다. 따라서, Pattern 인스턴스를 미리 캐싱해 두고, 나중에 isRomanNumeral() 메서드가 호출될 때마다 이 인스턴스를 재사용하는 것이 좋다.
public class RomanNumerals {
private static final Pattern ROMAN = Pattern.compile(
"^(?=.)M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
public static boolean isRomanNumeral(String s) {
return ROMAN.matcher(s).matches();
}
}
주의 사항
위의 모든 예시에서 불필요한 객체를 캐싱할 때 모두 불변 객체로 만들었다. 그래야 재사용해도 안전하기 때문이다. 하지만 불변 객체로 재사용을 한다는 직관에 반대되는 경우가 있다.
어댑터(뷰)는 실제 작업은 뒷단 객체에 위임하고, 자신은 제 2의 인터페이스 역할을 해 주는 객체다. 어댑터는 뒷단 객체만 관리하면 되므로 뒷단 객체 하나당 어댑터 하나씩만 만들어 주면 된다.
예를 들어, Map 인터페이스의 keySet() 메서드는 Map 객체 안의 키 전부를 담은 Set 뷰를 반환한다. 사용자는 keySet() 메서드를 호출할 때마다 새로운 Set 인스턴스가 만들어지리라 생각할 수 있지만, 실제 JDK 구현 내용을 보면 매번 같은 가변 Set 인스턴스를 반환한다.
이것은 반환된 Set 인스턴스는 가변일지라도 수행하는 기능이 모두 동일하고, 모든 Set 인스턴스가 Map 인스턴스를 대변하기 때문이다. 따라서 keySet() 이 뷰 객체를 여러 개 만들어도 상관은 없지만, 그럴 필요도 이득도 없다.
public class UsingKeySet {
public static void main(String[] args) {
Map<String, Integer> menu = new HashMap<>();
menu.put("Burger", 8);
menu.put("Pizza", 9);
Set<String> names1 = menu.keySet();
Set<String> names2 = menu.keySet();
names1.remove("Burger");
System.out.println(names1.size()); // 1
System.out.println(names2.size()); // 1
}
}
따라서 위와 같이 names1 인스턴스를 수정하게 되면, names2 인스턴스도 같이 영향을 받게 된다.
하지만 개인적으로 keySet() 메서드의 반환 값은 방어적 복사를 사용하여 매번 새로운 객체를 반환하는 방식이 옳다고 생각한다. 만약 keySet() 메서드로 받은 Set 인스턴스가 다른 곳에서도 사용 중이고, 이 인스턴스의 상태를 변화시키는 코드가 있다면, 현재 사용 중인 Set 인스턴스와 Map 인스턴스의 값에 확신을 할 수 없게 된다.
또한, keySet() 을 과도하게 많이 사용하는 환경이 아닌 이상, Set 인터페이스가 매번 생성된다고 성능에 치명적인 영향을 끼치지는 않는다. 차라리 Set 인터페이스를 불변 객체로 만들어서 안정적으로 유지 보수를 수행하는 것이 낫다고 생각한다.
오토 박싱
오토 박싱은 프로그래머가 기본 타입과 래퍼 타입을 섞어 쓸 때 자동으로 상호 변환해 주는 기술이다. 하지만 오토 박싱은 기본 타입과 래퍼 타입의 구분을 흐려줄 뿐, 완전히 없애 주는 것은 아니다.
public static long sum() {
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}
로직상 문제는 없지만, 성능적으로 매우 비효율적인 코드다. 이것의 원인은 바로 sum의 타입과 for문 내의 있는 i의 타입에 있다.
sum의 타입은 Long 타입이고, i는 long 타입이다. 즉, long 타입인 i는 반복문을 돌면서 sum에 더해질 때마다 새로운 Long 인스턴스를 만들게 된다. 결과적으로, 래퍼 타입보다는 기본 타입을 사용하고 의도치 않은 오토 박싱이 사용되지 않도록 주의해야 한다.
오해하지 말아야 할 부분
불필요한 객체 생성을 피하라는 것을 단순하게 객체 생성의 비용이 크니까 피해야 한다.로 오해하면 안 된다.
특히 요즘 JVM에서 불필요하게 생성된 작은 객체를 생성 및 회수하는 일은 별로 부담되는 작업이 아니다. 그러므로 데이터베이스 연결과 같이 비용이 매우 큰 객체가 아니라면, 커스텀 객체 풀을 만들지 말자.
더 나아가, 방어적 복사가 필요한 상황에서 객체를 재사용할 때의 피해가, 필요 없는 객체를 반복 생성했을 때의 피해보다 훨씬 크다는 사실을 기억하자. 반복 생성의 부작용은 코드 형태와 성능에만 영향을 주지만, 방어적 복사가 실패하면 버그와 보안 문제로 직행한다.
출처
'스터디 > 이펙티브 자바 스터디' 카테고리의 다른 글
| [이펙티브 자바] 아이템 5. 자원을 명시하지 말고 의존 객체 주입을 사용하라 (0) | 2022.04.18 |
|---|---|
| [이펙티브 자바] 아이템 4. 인스턴스화를 막으려거든 private 생성자를 사용하라 (0) | 2022.04.18 |
| [이펙티브 자바] 아이템 3. private 생성자나 열거 타입으로 싱글턴임을 보증하라 (0) | 2022.04.17 |
| [이펙티브 자바] 아이템 2. 생성자에 매개변수가 많다면 빌더를 고려하라 (2) | 2022.04.17 |
| [이펙티브 자바] 아이템 1. 생성자 대신 정적 팩터리 메서드를 고려하라 (0) | 2022.04.17 |
댓글