

[JPA] QueryDSL, 네이티브 SQL, 객체지향 쿼리 심화
jpa-study에서 스터디를 진행하고 있습니다.
QueryDSL
- JPA Criteria는 문자가 아닌 코드로 JPQL을 작성하므로 문법 오류를 컴파일 단계에서 잡을 수 있지만, 너무 복잡하고 어려워서 어떤 JPQL이 생성될지 파악하기가 어렵다.
- 이러한 단점을 보완하기 위해 오픈 소스 기반 프로젝트인 QueryDSL이 등장하였다.
- QueryDSL은 이름 그대로 쿼리 즉 데이터를 조회하는 데 기능이 특화되어 있다.
QueryDSL 시작
public void queryDSL() {
EntityManager em = emf.createEntityManager();
JPAQuery query = new JPAQuery(em);
QMember qMember = new QMember("m");
List<Member> members =
query.from(qMember)
.where(qMember.name.eq("회원1"))
.orderBy(qMember.name.desc())
.list(qMember);
}
QueryDSL을 사용하려면 com.mysema.query.jpa.impl.JPAQuery 객체를 생성해야 하며, 사용할 쿼리 타입(Q)을 생성할 때 생성자에는 별칭을 주면 된다. 이후 메소드는 일반 쿼리에서도 나오는 문법이라 이해하기 쉽다.
참고로 쿼리 타입은 QueryDSL 환경 설정을 수행하면 자동으로 지정한 소스 경로에 추가된다.
검색 조건 쿼리
JPAQuery query = new JPAQuery(em);
QItem item = QItem.item; // QItem을 정적으로 커스텀 선언하여 가져올 수도 있음.
List<Item> list = query.from(item)
.where(item.name.eq("좋은 상품").and(item.price.gt(20000))
.list(item);
where 절에는 and나 or을 사용할 수 있고, 조건절에서 between, contains와 같은 기능도 제공하고 있다.
결과 조회
uniqueResult(): 조회 결과가 한 건일 때 사용. 2개 이상이면 예외 발생singleResult(): 조회 결과가 2개 이상이면 처음 데이터를 반환. 그렇지 않으면 1개의 데이터를 그대로 반환list(): 결과가 여러 개일 때 모두 반환하며, 결과가 없으면 빈 컬렉션을 반환
페이징과 정렬
QItem item = QItem.item;
query.from(item)
.where(item.price.gt(20000))
.orderBy(item.price.desc(), item.stockQuantity.asc())
.offset(10).limit(20)
.list(item);
정렬은 orderBy를 사용하고 페이징은 offset과 limit을 사용하면 된다.
그룹
query.from(item)
.groupBy(ite.price)
.having(item.price.gt(1000))
.list(item);
그룹화하려면 groupBy를 사용하고 그룹화된 결과를 제한하려면 having을 사용하면 된다.
조인
- innerJoin, leftJoin, rightJoin, fullJoin, fetchJoin을 사용할 수 있다.
// 기본 조인
QOrder order = QOrder.order;
QMember member = QMember.member;
QOrderItem orderItem = QOrderItem.orderItem;
query.from(order)
.join(order.member, member)
.leftJoin(order.orderItems, orderItem)
.list(order);
// 조인 on 사용
query.from(order)
.leftJoin(order.orderItems, orderItem)
.on(orderItem.cont.gt(2))
.list(order);
// 페치 조인
query.from(order)
.innerJoin(order.member, member).fetch()
.leftJoin(order.orderItems, orderItem).fetch()
.list(order);
// 세타 조인
qquery.from(order, member)
.where(order.member.eq(member))
.list(order);
서브 쿼리
com.mysema.query.jpa.JPASubQuery 를 생성하여 서브 쿼리를 사용한다. 서브 쿼리의 결과가 하나면 unique() , 여러 개면 list() 를 사용한다.
QItem item = QItem.item;
QItem itemSub = new QItem("itemSub");
query.from(item)
.where(item.price.eq(
new JPASubQuery().from(itemSub).unique(itemSub.price.max())
))
.list(item);
프로젝션과 결과 반환
- select 절에 조회 대상을 지정하는 것을 프로젝션이라 한다.
프로젝션 대상이 하나
QItem item = QItem.item;
List<String> result = query.from(item).list(item.name);
item.name 자료형에 맞는 타입으로 바로 매핑하면 된다.
여러 컬럼 반환과 튜플
QItem item = QItem.item;
List<Tuple> result = query.from(item).list(item.name, list.price);
// tuple.get(item.name), tuple.get(item.price)와 같이 사용해야 함.
QueryDSL은 Map과 비슷한 Tuple 자료형을 지원한다. 이를 이용하여 여러 컬럼을 사용할 수 있다.
빈 생성
쿼리 결과를 특정 객체로 받고 싶으면 QueryDSL의 빈 생성 기능을 사용할 수 있다.
public class ItemDTO {
private String username;
private int price;
// 생성자
// getter, setter
먼저 반환 값을 매핑할 객체를 선언한다.
QItem item = QItem.item;
List<ItemDTO> result = query.from(item).list(
Projections.bean(ItemDTO.class, item.name.as("username"), item.price));
Projections.bean() 메소드는 setter를 사용해서 값을 채워 준다. 또한, 쿼리 결과와 매핑할 프로퍼티 이름이 다르면 as를 사용해서 별칭을 주면 된다.
QItem item = QItem.item;
List<ItemDTO> result = query.from(item).list(
Projections.fields(ItemDTO.class, item.name.as("username"), item.price));
Projections.fields() 는 필드에 직접 접근해서 값을 채워 준다. 필드를 private으로 설정해도 동작한다.
QItem item = QItem.item;
List<ItemDTO> result = query.from(item).list(
Projections.constructor(ItemDTO.class, item.name.as("username"), item.price));
Projections.constructor() 는 생성자를 사용한다. 이때 지정한 프로젝션과 파라미터 순서가 동일한 생성자가 필요하다.
수정, 삭제 배치 쿼리
QueryDSL은 영속성 컨텍스트를 무시하고 데이터베이스를 직접 쿼리하여 수정, 삭제 같은 배치 쿼리를 지원한다.
com.mysema.query.jpa.impl.JPAUpdate.Clause 를 사용하여 배치 쿼리를 날릴 수 있다.
QItem item = QItem.item;
JPAUpdateClause updateClause = new JPAUpdateClause(em, item);
long count = updateClause.where(item.name.eq("시골 개발자의 JPA 책"))
.set(item.price, item.price.add(100))
.execute();
동적 쿼리
com.mysema.query.BooleanBuilder 를 사용하여 특정 조건에 따른 동적 쿼리를 생성할 수 있다.
SearchParam param = new SearchParam();
param.setName("시골 개발자");
param.setPrice(10000);
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if (StringUtils.hasText("param.getName()) {
builder.and(item.name.contains(param.getName()));
}
if (param.getPrice() != null) {
builder.and(item.price.gt(param.getprice());
}
List<Item> result = query.from(item)
.where(builder)
.list(item);
네이티브 SQL
- 때로는 데이터베이스에 종속적인 기능을 사용해야 할 때가 있다.
- 네이티브 SQL은 개발자가 직접 정의하는 것이고, 영속성 컨텍스트의 기능을 그대로 사용할 수 있다.
- 네이티브 SQL은 SQL만 직접 작성하는 것일 뿐 나머지는 JPQL을 사용할 때와 같다는 것을 명심해야 한다.
네이티브 SQL 사용
엔티티 조회
// 결과 타입 정의
public Query createNativeQuery(String sql, class resultClass);
// 결과 타입을 정의할 수 없을 때
public Query createNativeQuery(String sql);
// 결과 매핑 사용 -> 주로 엔티티와 스칼라 값을 함께 조회할 때 쓰임.
public Query createNativeQuery(String sql, String resultSetMapping);
Named 네이티브 SQL
JPQL처럼 Named 네이티브 SQL을 사용해서 정적 SQL을 작성할 수 있다.
@Entity
@NamedNativeQuery(
name = "Member.memberSQL",
query = "SELECT ID, AGE, NAME, TEAM_ID FROM MEMBER WHERE AGE > ?",
resultclass = Member.class
)
public Member {
...
}
이를 사용하는 예제는 다음과 같다.
TypedQuery<Member> nativeQuery =
em.createNamedQuery("Member.memberSQL", Member.class)
.setParameter(1, 20);
흥미로운 점은 JPQL Named 쿼리와 같은 createNamedQuery() 메소드를 사용하므로 TypeQuery를 반환 값으로 이용할 수 있다.
@NamedNativeQuery의 속성
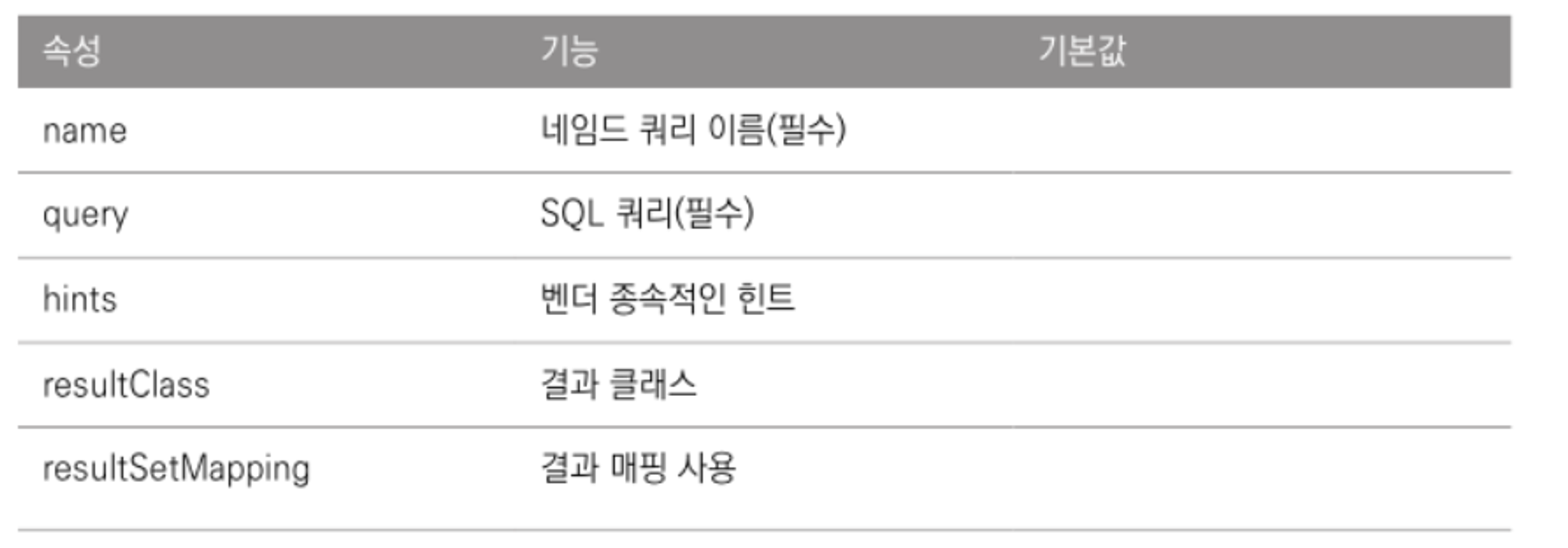
객체 지향 쿼리 심화
벌크 연산
- 여러 건은 한 번에 삽입, 수정하거나 삭제하는 연산을 벌크 연산이라고 한다.
- JPA 표준에서는 수정 및 삭제 벌크 연산을
executeUpdate()메소드를 사용하여 구현할 수 있다.
// 수정
String query = "update Product p set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount =
em.createuery(query)
.setParameter("stockAmount", 10)
.executeUpdate();
// 삭제
String query = "delete from Product p where p.price < :price";
int resultCount =
em.createuery(query)
.setParameter("price", 100)
.executeUpdate();
- 단 하이버네이트는 삽입 연산도
executeUpdate()메소드를 통해 벌크 연산이 가능하다.
벌크 연산의 주의점
- 벌크 연산은 영속성 컨텍스트와 2차 캐시를 무시하고 데이터베이스에 직접 쿼리한다.
- 위 특징으로 인해 아래 시나리오가 발생할 수 있다.
- 가격이 1000원인 상품 A를 조회하였다. 조회된 상품 A는 영속성 컨텍스트에서 관리된다.
- 벌크 연산으로 모든 상품의 가격을 10% 상승시켰다. 따라서 상품 A의 가격은 1100원이 되어야 한다.
- 벌크 연산을 수행한 후에 상품 A의 가격을 출력하면 기대했던 1100원이 아니라 1000원이 출력된다.
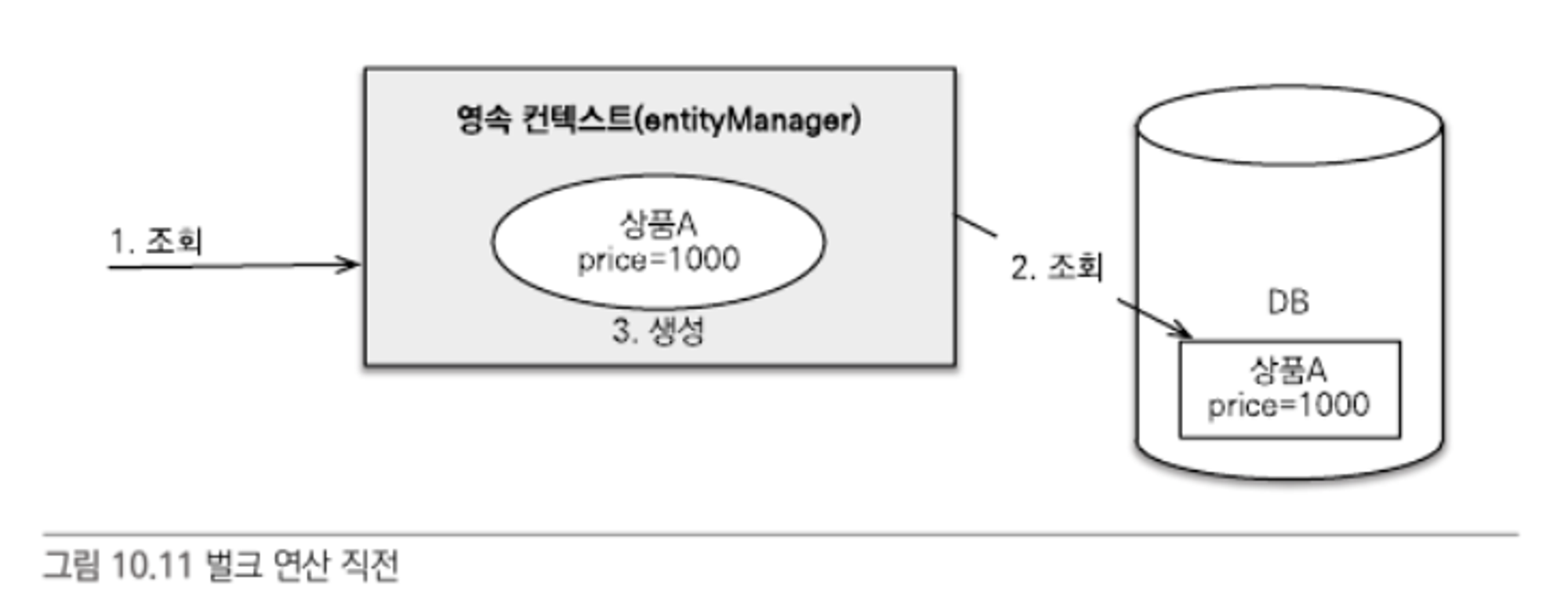
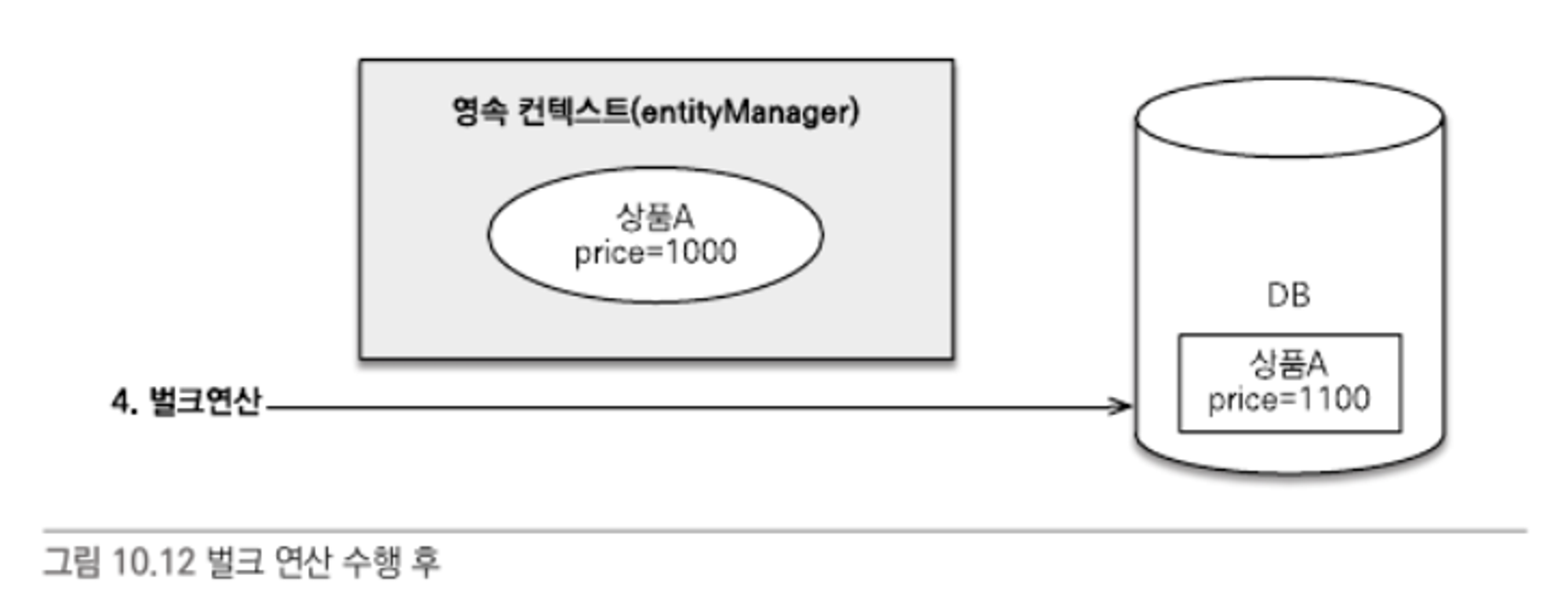
벌크 연산의 문제점을 해결하는 방법
em.refresh()메소드 사용- 벌크 연산을 수행한 직후에 정확한 상품 A 엔티티를 사용해야 한다면
em.refresh()를 사용하여 데이터베이스에서 상품 A를 다시 조회하면 된다. em.refresh(productA)
- 벌크 연산을 수행한 직후에 정확한 상품 A 엔티티를 사용해야 한다면
- 벌크 연산 먼저 실행
- 가장 실용적인 해결책이다.
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
- 영속성 컨텍스트 자체를 초기화하면 추후 데이터베이스에서 조회하여 영속성 컨텍스트에 엔티티를 저장하면 된다.
영속성 컨텍스트와 JPQL
쿼리 후 영속성 상태인 것과 아닌 것
- 조회한 엔티티만 영속성 컨텍스트가 관리한다.
- 임베디드 타입은 조회하여 값을 변경해도 영속성 컨텍스트가 관리하지 않는다.
JPQL로 조회한 엔티티와 영속성 컨텍스트
- JPQL로 데이터베이스에서 조회한 엔티티가 영속성 컨텍스트에 이미 있으면 JPQL로 데이터베이스에서 조회한 결과를 버리고 대신에 영속성 컨텍스트에 있던 엔티티를 반환한다.
- 구체적인 방식은 아래에서 설명한다.
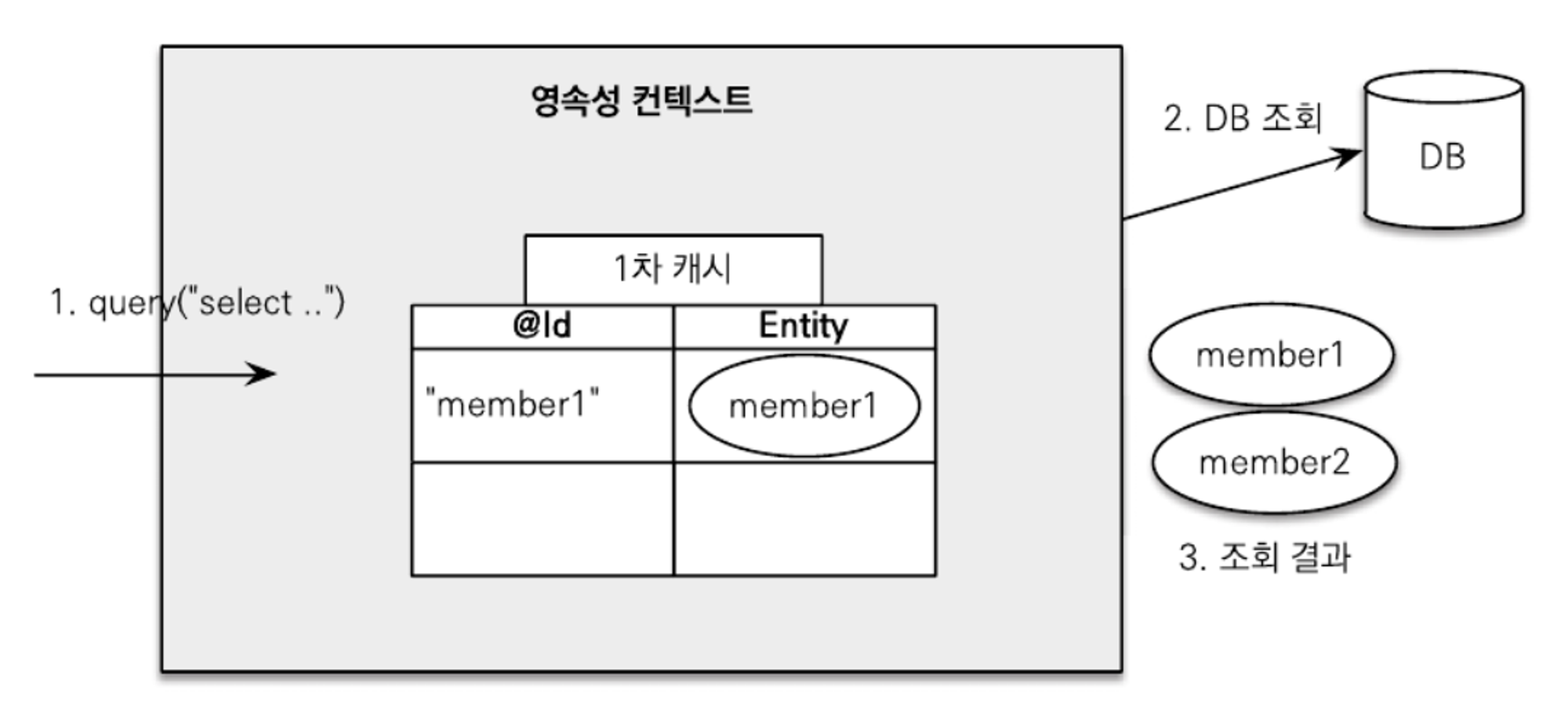
1. JPQL을 사용해서 조회를 요청한다.
2. JPQL은 SQL로 변환되어 데이터베이스를 조회한다.
3. 조회한 결과와 영속성 컨텍스트를 비교한다.
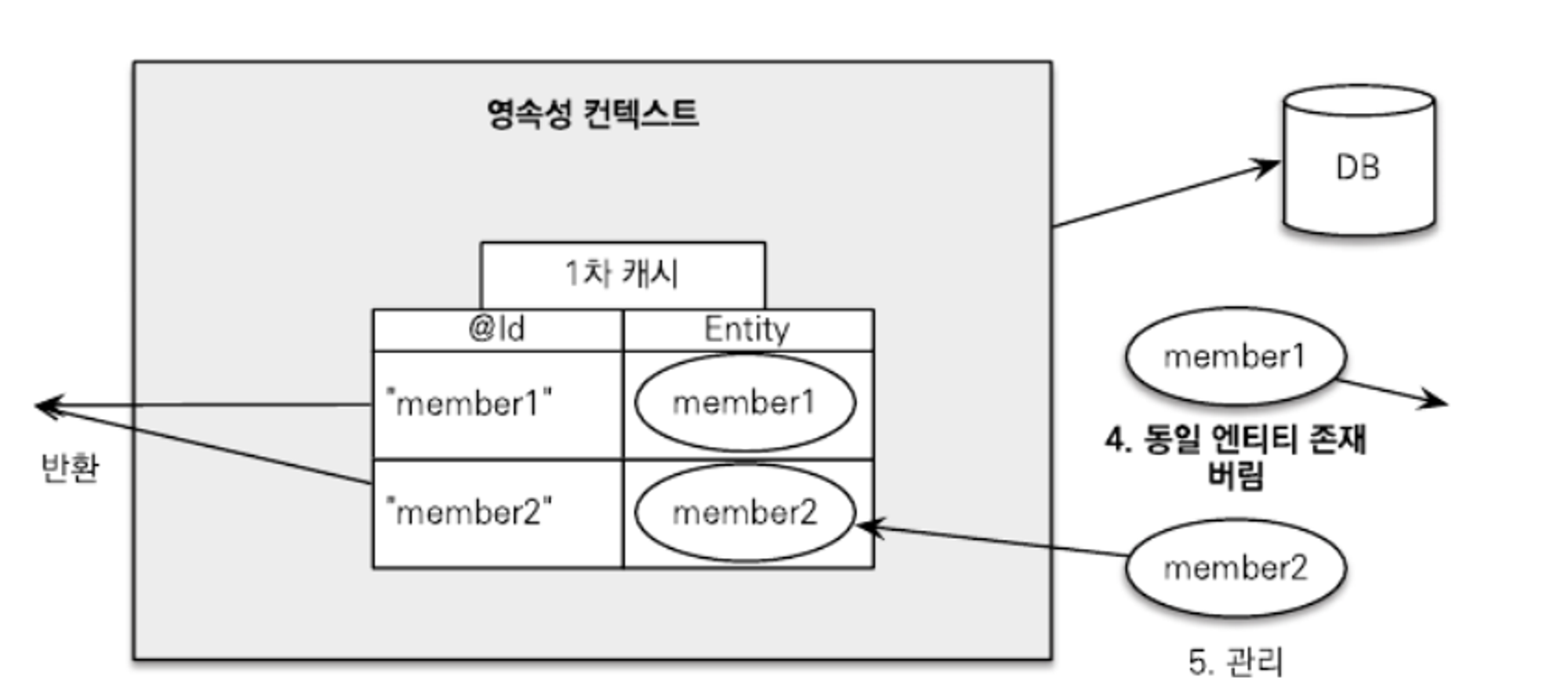
4. 식별자 값을 기준으로 member1은 이미 영속성 컨텍스트에 있으므로 버리고 기존에 있던 member1이 반환 대상이 된다.
5. 식별자 값을 기준으로 member2는 영속성 컨텍스트에 없으므로 영속성 컨텍스트에 추가한다.
6. 쿼리 결과인 member1, member2를 반환한다. 여기서 member1은 쿼리 결과가 아닌 영속성 컨텍스트에 있던 엔티티다.
find() vs JPQL
em.find()메소드는 엔티티를 영속성 컨텍스트에서 먼저 찾고 없으면 데이터베이스에서 찾는다.- JPQL은 항상 데이터베이스에 SQL을 실행하여 결과를 조회한다.
- JPQ 구현체 개발자 입장에서
em.find()메소드는 파라미터로 식별자로 넘기기 때문에 영속성 컨텍스트를 조회하기 쉽지만, JPQL을 분석하여 영속성 컨텍스트를 조회하는 것은 쉬운 일이 아니었을 것이기 때문이다.
- JPQ 구현체 개발자 입장에서
JPQL과 플러시 모드
- 플러시는 영속성 컨텍스트의 변경 내역을 데이터베이스에 동기화하는 것이다.
- 플러시 모드는 FlushModeType.AUTO와 FlushModeType.COMMIT가 있는데 전자는 커밋 또는 쿼리 실행 시 플러시를 하고, 후자는 커밋 시에만 플러시를 한다. 후자는 반드시 성능 최적화가 필요할 때 주의하여 사용해야 한다.
쿼리와 플러시 모드
- JPQL은 영속성 컨텍스트에 있는 데이터를 고려하지 않고 데이터베이스에서 데이터를 조회한다.
- 따라서 JPQL을 실행하기 전에 영속성 컨텍스트의 내용을 데이터베이스에 반영해야 한다.
product.setPrice(2000); // 가격을 1000 -> 2000원으로 변경
Product product2 =
em.createQuery("select p from Product p where p.price = 2000",
Product.class)
.getSingleResult();
- 위 예제에서 플러시 모드가 AUTO이므로 쿼리 실행 직전에 영속성 컨텍스트가 플러시된다. 만약 플러시 모드가 COMMIT이라면 쿼리 실행 직전에 영속성 컨텍스트가 플러시되지 않으므로 데이터 무결성 문제가 발생할 수 있다.
플러시 모드와 최적화
- FlushMode.COMMIT 모드는 트랜잭션을 커밋할 때만 플러시가 일어난다.
- 플러시가 너무 자주 일어나는 상황에 이 모드를 사용하면 쿼리 시 발생하는 플러시 횟수를 줄여서 성능을 최적화할 수 있다.
- ex) 등록() - 쿼리() - 등록() - 쿼리() - 등록() - 쿼리() ...
출처
김영한 - 자바 ORM 표준 JPA 프로그래밍
'스터디 > JPA 스터디' 카테고리의 다른 글
| [JPA] 웹 애플리케이션과 영속성 관리 (0) | 2022.02.09 |
|---|---|
| [JPA] 스프링 데이터 JPA (0) | 2022.02.05 |
| [JPQ] 객체 지향 쿼리 소개, JPQL (0) | 2022.01.20 |
| [JPA] Qna 미션을 통해 새롭게 배운 내용 정리 (0) | 2022.01.17 |
| [JPA] 값 타입 (0) | 2022.01.01 |
댓글