

와탭랩스가 알려 주는 모니터링 기초 웨비나 후기
안녕하세요? 제이온입니다.
어제는 회사에서 와탭랩스가 알려주는 모니터링 기초 웨비나를 수강하였습니다. 후기에 앞서, 웨비나 강연에서 배운 내용을 정리하려고 합니다.
모니터링의 정의
- 특정한 것을 발견하기 위해 상황을 주의 깊게 관찰하고 확인하는 행위
- 장애와 오류를 발견하기 위해 IT 서비스 요소를 관찰하고 확인하는 행위
왜 우리는 모니터링을 해야 하나요?
- "장애를 잘 인지하고 싶어요."
- 그렇다면 무엇이 장애입니까?
- "장애를 예방할 수 있다."
- 어떤 상황이 장애 상황인가요?
- "안정적인 서비스를 제공할 수 있다."
- 안정적인 서비스, 불안정한 서비스는 어떤 기준으로 구분해야 하나요?
장애를 관리하고 싶다면?
장애를 관리하고 싶다면 장애와 안정의 기준을 올바르게 정의해야 합니다.
잘못된 장애 기준과 안정성 정의
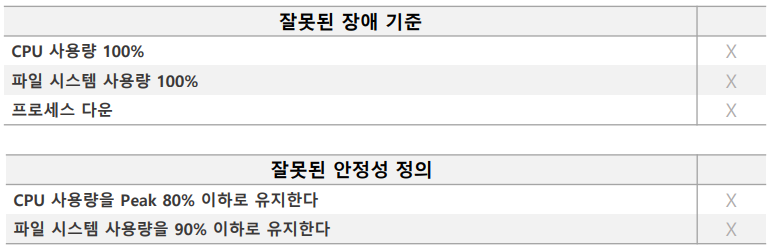
올바른 장애 기준과 안정성 정의

장애, 장애 현상, 장애 원인
장애
사용자 요청에 서비스가 정상 응답하지 못하는 현상
장애 현상
- CPU 사용량 급증에 따른 응답 지연
- 프로세스 Down으로 무응답
장애 원인
- CPU 사용량 급증에 따른 응답 지연
- 특정 애플리케이션 로직 오류로 과도한 메모리 사용, 메모리 부족에 따른 잦은 GC 수행
- 프로세스 down으로 인한 무응답
- 애플리케이션 Moemory Access Viloation으로 프로세스 Down
- Fail-Over에 3분 소요
모니터링 해야 하는 것은?
장애 인지, 현상, 원인 모두 모니터링해야합니다.
장애를 인지할 수 있는 지표
- APDEX, TPS, 평균 응답 시간
장애 현상을 나타내는 지표
- CPU, 메모리, 네트워크 자원 등 리소스 사용량
- Port 오픈, 프로세스 Down 등
장애 원인 분석에 필요한 정보
- Log, 세부적인 리소스 사용량 정보, Stack 정보
누가 모니터링 하나요?
장애와 안정성 저해를 유발하는 요소는 너무 많습니다. 이 많은 요소들을 사람이 휴일 없이 24시간 지켜 볼 수는 없습니다. 따라서 모니터링은 사람이 아닌 도구가 해야 합니다.
모니터링은 도구에 맡기고, 도구에게 이상 요소를 발견하면 알려 달라고 해야 합니다. 즉, 사람은 알람을 관리하고 근본 원인을 추적해 조치하는 역할을 합니다.
제 1단계 - 내 서비스 목표 수준을 정의합니다.
범용 기준

고려 사항
- 시스템, 인력 한계에 기반해서 목표치를 설정할 것
- 최대한 단순하게 정의할 것
제 2단계 - 목표 수준 달성에 방해 요소를 파악합니다.
모니터링 도구로 파악합니다.

제 3단계 - 방해 요소의 원인을 개선합니다.
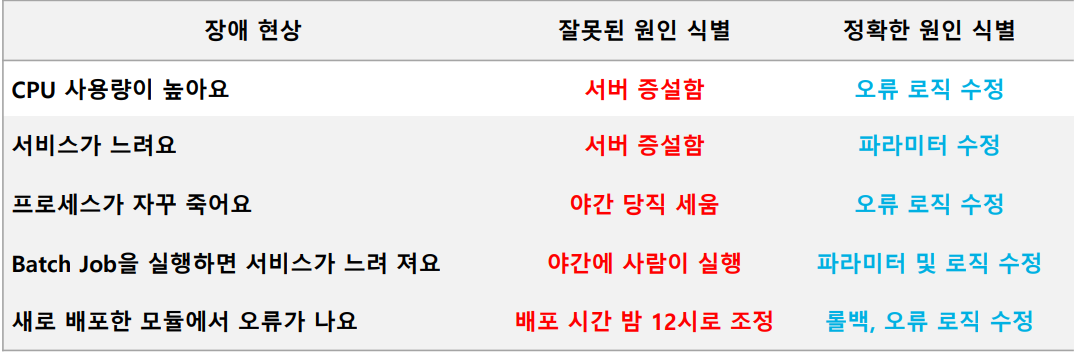
프로그램 오류를 수정하고, 서버 자원을 재분배하며 인지한 걸림돌을 개선합니다. 이 단계에서는 현상과 원인을 혼동하지 않는 것이 중요합니다.
CPU 사용량이 높다 (현상)
어떤 프로세스인가? → 애플리케이션 소스가 어디인가(원인) → 수정
프로세스가 다운되었다 (현상)
다운 전후의 정보 → 정보를 통한 분석 (원인) → 수정
Case - 슬픈 사례
출근하자 마자 타 부서에서 전화가 왔습니다. 서비스 이용이 되지 않는다는 문의입니다.
여러 서버들을 열심히 찾아보니 프로세스 하나가 죽어 있습니다.
언제 죽었는지, 왜 죽었는지 알 수 없지만 프로세스를 다시 살리고 서비스를 확인 합니다.
이후 문의한 부서에 조치되었음을 알립니다.
잠시 후 다시 전화가 옵니다..
Case - 일반적인 사례
많은 시간을 투자해 힘들게 알람을 구성했기에 본업에 집중하는 중 Email로 알람을 받습니다.
X 서버의 Y 프로세스가 다운 되었다는 알람 입니다.
프로세스를 다시 살리고 서비스를 확인 합니다.
본업을 멈추고 여러 로그와 정황 정보를 통해 분석을 시작합니다.
분석이 맞는지 확신이 서지 않지만 의심되는 부분을 조치 했습니다.
다음날 같은 알람을 또 받습니다..
올바른 모니터링을 해야 하는 이유
장애의 정확한 원인을 식별하는 것이 매우 중요합니다.
많은 지표 중에 무엇부터 보아야 하나요? - 인프라 관점
1. CPU 사용량
메모리가 부족해도, Disk I/O가 높아도 CPU 사용량이 증가합니다.
2. CPU 사용량 세부 지표
CPI I/O Wait, CPU Steal, CPU System, CPU User 등 각각의 요소로 구분해 세부 요인을 봅니다.
3. 세부 요인 식별
어떤 프로세스가 리소스를 과점유하는지, Disk I/O나 메모리가 부족에서 기인하지 않았는지 확인합니다.
4. 분석 - 메트릭스 차트를 펼칩니다.
netstat, file descriptor, 프로세스별 상세 자원 정보를 확인합니다.
많은 지표 중에 무엇부터 보아야 하나요? - 애플리케이션 관점
1. Apdex
Apdex에 100을 곱한 값이 서비스 목표 수준입니다. 수치 변화가 크거나 0.9보다 낮다면 시급한 개선이 필요합니다.
2. 히트맵
히트맵 상단의 점들을 드래그해서 애플리케이션 어느 구간에서 지연이 발생하는지 확인하세요.
TPS, 사용자 수
내 서비스를 얼마나 많은 사람들이 사용하는지 확인하세요.
분석 - 메트릭스 차트를 펼칩니다.
netstat, file descriptor, 프로세스별 상세 자원 정보를 확인합니다.
웨비나 후기
최근 회사 업무로 모니터링 관련된 지표를 데이터 시각화하면 좋겠다는 요청을 받았습니다. 해당 업무는 모니터링 지표 관련 DB 테이블에서 값을 꺼내서 UI로 뿌려 주는 것이지만, 모니터링을 수행하는 과정과 어떤 지표를 모니터링으로 삼는지 궁금했습니다. 마침 좋은 웨비나를 직장 동료분이 추천해 주셨고, 기초를 다지기 좋은 시간이었다고 생각합니다.
특히, 올바른 모니터링에 초점을 맞춰서 현상과 원인을 구분하여 정확한 원인을 식별하는 것에 중요성을 느낄 수 있었습니다. 저 또한 과거에 우테코 다라쓰 팀 프로젝트를 하면서 허용된 DB 커넥션 양이 초과되는 현상을 보고, 원인을 못 찾아서 DB 커넥션 허용 수치를 늘리는 식으로 대응했었는데, 결국 나중에 똑같은 현상을 반복하는 경험을 한 적이 있습니다. 결국 원인을 찾는데 굉장히 많은 시간이 걸렸습니다. 만약 올바른 모니터링을 수행했으면 원인을 찾기 더 쉽지 않았을까 생각이 듭니다.
전반적으로 강사님이 친절하면서도 천천히 잘 설명해 주셔서 유익한 시간이었다고 생각합니다. 발표 이후 와탭랩스 사의 모니터링 솔루션을 이용하여 각종 지표를 관찰하는 경험도 재밌었습니다.
출처
https://www.youtube.com/watch?v=9luf690CkA0&ab_channel=WhaTap
'각종 후기 > IT 행사' 카테고리의 다른 글
| [2021 DEV CARNIVAL - 데브 카니발] 코딩 테스트 결과 발표 (0) | 2021.05.28 |
|---|---|
| [2021 DEV CARNIVAL - 데브 카니발] 코딩 테스트 후기 (0) | 2021.05.22 |
| [2021 카카오 블라인드 신입 개발자 공채] 1차 코딩 테스트 결과 발표 (4) | 2020.09.17 |
| [2021 카카오 블라인드 신입 개발자 공채] 1차 코딩 테스트 후기 (0) | 2020.09.12 |
| 네이버 부스트캠프 1차 코딩테스트 결과 발표 (0) | 2020.07.09 |
댓글