

[우아한 테크코스 3기] LEVEL 2 회고 (94일차)

안녕하세요? 제이온입니다.
오늘도 중간곰과 함께 루터회관에서 지하철 노선도 관리 미션 3단계를 진행했습니다.
지하철 노선도 관리 미션 소개
3단계에서 달라진 점은 구간 추가입니다. 그 전까지는 구간에 대한 개념 없이도 API 설계가 잘만 돌아갔는데, 구간이 생김으로써 여러 가지 기능을 구현해야 했습니다.

위와 같이 노선 추가할 때, 새로운 정보를 추가로 담아서 request로 보내야합니다.

그 외에 구간을 추가하는 API도 만들어야 하고, 아래처럼 노선 조회할 때 지하철역 정보도 함께 보여주어야 합니다.

구간 제거도 존재하지만, API가 간단해서 따로 설명하지는 않겠습니다.
페어 프로그래밍
원래 2단계까지가 페어로 진행하는 것이 원칙이었으나, 중간곰과 합의를 봐서 3단계까지 모두 구현하기로 하였습니다. 오늘 배운 것도 많고, 느낀 점도 상당히 많았지만 제가 너무 피곤해서 기억나는 부분만 기록하려고 합니다.
(1) 구간 등록 후 정렬하는 과정
구간을 등록하는 것은 간단합니다. 노선을 설정하고, 특정 지하철역 2개를 고르면 됩니다. 예외 처리를 고려하지 않다고 가정하면, 이것이 끝입니다. 하지만, DB에 들어가는 구간의 순서는 보장되지 않습니다. 예를 들어, 현재 2호선의 구간이 "강남역-잠실역-교대역-역삼역"이라고 할 때, DB에는 반드시 "강남역-잠실역, 잠실역-교대역, 교대역-역삼역"의 순서를 보장하지 않는다는 것입니다. 그래서 DB에서 가져온 구간 정보를 토대로 원래의 구간 순서로 정렬해 주어야 합니다.
이것을 구현하는 방법은 생각보다 간단합니다. 해당 역들이 나온 횟수를 세 보는 것이죠. 상행 종점역과 하행 종점역은 한 번만 등장할 것이고, 나머지 역들은 2번씩 등장할 것입니다. DB에 "잠실역-교대역, 강남역-잠실역, 교대역-역삼역"의 순서로 저장되어있다고 가정하면, 잠실역은 2번, 교대역은 2번, 강남역은 1번, 역삼역은 1번이므로 강남역과 역삼역이 종점역이 되는 것입니다. 그리고 Section 객체의 상행역과 하행역 정보를 통해서 강남역과 역삼역 중에 무엇이 상행 종점역이고 하행 종점역인지 판단할 수 있습니다.
모든 코드를 수록하지는 않겠으나, 핵심 메소드는 아래와 같습니다.
private List<Section> sort(final List<Section> sections) {
if (sections.size() < 2) {
return sections;
}
final Section from = decideUpStation(sections);
final List<Section> sortedSections = new ArrayList<>();
sortedSections.add(from);
findNextSection(from, sections, sortedSections);
return sortedSections;
}
구간이 2개 미만이면 정렬이 의미가 없으므로 바로 반환하고, decideUpStation() 메소드를 통해 상행 종점역을 얻어 옵니다. 그리고 우리가 원하는 형태로 정렬된 결과 리스트를 생성하고 상행 종점역이 있는 구간을 담습니다. 그리고 findNextSection() 메소드를 통해 나머지 구간들을 담습니다.
(2) 람다식에서 자기 자신을 표현하는 방법
코드를 작성하다 보니, List를 Map으로 바꿔야 할 일이 생겼습니다. List<Station>에 대하여, Key가 Station_id이고, Value가 Station인 Map을 만들어야하는 것이죠. toMap()을 통해 이를 구현할 수 있는데, 문제는 Value가 자기 자신 즉, Station이므로 "station -> station"이라는 람다식을 사용해야 합니다. 물론, 이것도 문제는 없으나 뭔가 좀 불-편했습니다. 그러다가 중간곰이 다른 방법을 제시해 주었습니다.
public void addStations(final List<Station> stations) {
stationGroup.putAll(stations.stream()
.collect(Collectors.toMap(Station::getId, Function.identity())));
}
바로 Function.identity() 메소드를 사용하는 것입니다. 넘어온 값을 그대로 반환해 주는 함수로 좀 더 고급져 보입니다.
(3) ArrayList.equals() vs Object.equals()
구간 정렬 테스트를 작성하던 중, 한 가지 의문점이 생겼습니다.
@Test
void sort() {
final List<Long> expected = Arrays.asList(3L, 2L, 1L, 4L, 5L);
final List<Section> sectionGroup = new ArrayList<>();
sectionGroup.add(new Section(1L, 3L, 2L, 10));
sectionGroup.add(new Section(1L, 4L, 5L, 5));
sectionGroup.add(new Section(1L, 2L, 1L, 6));
sectionGroup.add(new Section(1L, 1L, 4L, 8));
final Sections sections = new Sections(sectionGroup);
final List<Long> ids = sections.distinctStationIds();
assertThat(ids).isEqualTo(expected);
}
위 코드는 과연 성공을 할 것인가였죠. 리스트 2개가 순서가 같고 요소도 같은지 비교하는 것인데, 단순히 equals()만으로도 이것이 가능할 지 궁금했습니다. 직접 해 보니까 위 코드는 성공하고, List가 아니고 배열이면 실패합니다. 왜 그럴까요?
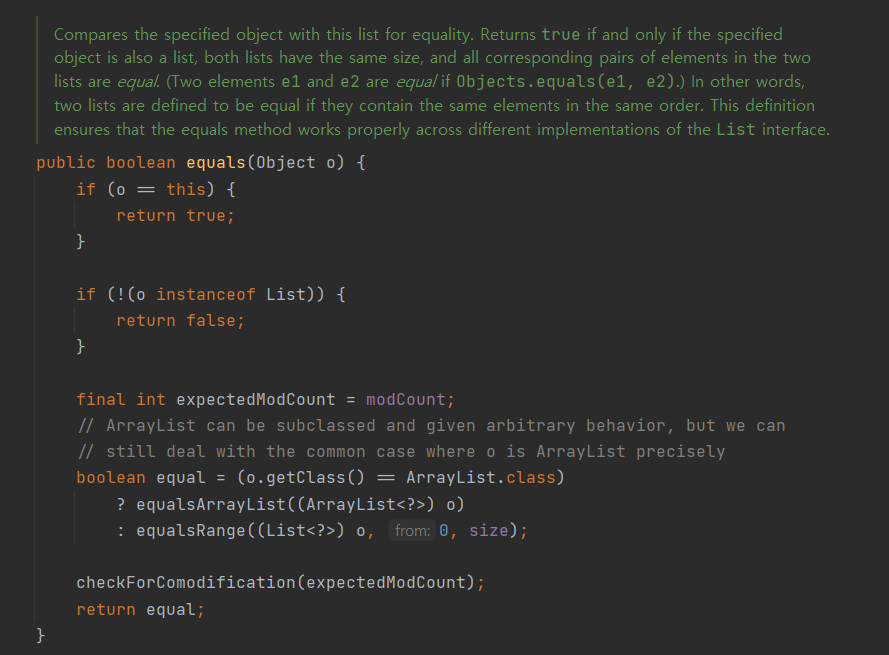
위는 ArrayList의 equals() 메소드입니다. 내용을 보면 원소 하나 하나를 비교하는 것을 알 수 있습니다.

하지만, 배열의 equals()는 ArrayList와는 달리 오버라이딩 없이 Object의 equals()를 사용하는 것을 알 수 있습니다. 결국, ArrayList에서 제가 원하는대로 equals() 비교가 이루어지는 이유는 ArrayList의 equals()가 재정의되었기 때문입니다.
(4) 응답 Body가 없을 때의 상태 코드는 204번 코드(No_Content)를 쓸 것
@PutMapping("/lines/{id}")
public ResponseEntity<Void> updateLine(@PathVariable Long id, @RequestBody LineRequest lineRequest) {
lineService.updateLine(id, lineRequest);
return ResponseEntity.ok().build();
}
위는 Line의 정보를 업데이트하는 역할을 합니다. 그리고 응답 Body는 없고 상태 코드는 200번 코드(OK)를 사용하는 것을 알 수 있습니다. 하지만, 중간곰의 리뷰어님인 미립의 말씀에 따르면 응답 Body가 없을 경우 상태 코드를 204번 코드로 쓰는 것이 맞다고 합니다.
(5) Auto_Increment로 설정된 id가 있는 테이블에서 save를 할 때 주의할 점
아래와 같은 테이블 구조가 있다고 가정합시다.
create table if not exists STATION
(
id bigint auto_increment not null,
name varchar(255) not null unique,
primary key(id)
);
그리고 id는 Auto_Increment이므로 데이터를 저장할 때 id를 따로 받지 않습니다. 따라서 Jdbc 템플릿을 이용한 save 코드는 아래와 같습니다.
public Station save(final Station station) {
final String sql = "INSERT INTO station (name) VALUES (?)";
final GeneratedKeyHolder keyHolder = new GeneratedKeyHolder();
final PreparedStatementCreator preparedStatementCreator = con -> {
final PreparedStatement preparedStatement = con.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
preparedStatement.setString(1, station.getName());
return preparedStatement;
};
jdbcTemplate.update(preparedStatementCreator, keyHolder);
final long id = keyHolder.getKey().longValue();
return new Station(id, station.getName());
}
이때 반환을 new 키워드를 통해 직접 Station 객체를 만들어 주는 것을 알 수 있습니다. 이러면 한 가지 문제가 발생합니다.
바로, Station 테이블의 Default 속성을 가진 created_time이 있다고 합시다. 이때, save()를 하고 반환값으로 단순히 new 키워드를 통해 반환한다면, 이 created_time은 null로 처리됩니다. 따라서, 직접 객체를 생성하지 말고 findById()를 통하여 DB에 한 번 더 쿼리를 날린 후 적합한 객체를 가져와야 합니다.
정리
오늘은 중간곰의 코드 리뷰에 따른 1, 2단계 미션 리팩토링 및 3단계 구간 등록을 어느 정도 구현하였습니다. 내일은 구간 등록 예외 처리 및 삭제까지 최대한 진행해 보려고 합니다.
'각종 후기 > 우아한테크코스' 카테고리의 다른 글
| [우아한 테크코스 3기] LEVEL 2 회고 - 지하철 노선도 관리 1, 2단계 미션 1차 피드백을 받아보다 (98일차) (2) | 2021.05.10 |
|---|---|
| [우아한 테크코스 3기] LEVEL 2 회고 (95일차) (2) | 2021.05.07 |
| [우아한 테크코스 3기] LEVEL 2 회고 (93일차) (0) | 2021.05.05 |
| [우아한 테크코스 3기] LEVEL 2 회고 (92일차) (4) | 2021.05.04 |
| [우아한 테크코스 3기] LEVEL 2 회고 (91일차) (4) | 2021.05.03 |
댓글