스터디/CS 스터디
[데이터 분산 처리] Kafka - What is Kafka
제이온 (Jayon)
2022. 1. 16. 18:13
cs-study에서 스터디를 진행하고 있습니다.
Kafka를 왜 개발하였을까?
카프카 이전 링크드인의 데이터 처리 시스템

- 각 파이프라인이 파편화 되고 시스템 복잡도가 높아 새로운 시스템을 확장하기 어려움.
- 기존 메시징 큐 시스템인 ActiveMQ는 링크드인의 수많은 트래픽과 데이터를 처리하기에 한계가 존재함.
- 그래서 다음과 같은 목표를 가지고 새로운 시스템을 개발함.
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일 아웃이 가능한 시스템
카프카 이후 링크드인의 데이터 처리 시스템

- 모든 이벤트/데이터의 흐름을 중앙에서 관리함.
- 서비스 아키텍처가 기존에 비해 관리하기가 용이함.
메시징 시스템
비교
일반적인 형태의 네트워크 통신의 문제점

- N:N 연결 → 클라이언트가 갑자기 많아질 경우 느려질 수 있고 이를 대응하기 위한 확장성이 떨어짐.
- 특정 클라이언트가 다운되어서 메시지를 받지 못할 경우 메시지가 유실될 수 있음.
Pub/Sub 모델

작동 방식
- Producer가 메시지를 Consumer에게 직접 전달하는 것이 아니라, 중간의 메시징 시스템에 전달함.
- 메시징 시스템의 교환기가 메시지의 수신처 ID의 값을 통해 Consumer의 큐에 메시지를 전달 (push)
- Consumer는 큐를 모니터링하다가 큐에 메시지가 있을 경우 값을 회수
장점
- 특정 개체가 수신 불능 상태가 되더라도 메시징 시스템만 살아있다면 메시지가 유실되지 않음.
- 메시징 시스템으로 연결되어 있으므로 확장성이 용이함.
단점
- 직접 통신하지 않기 때문에 메시지가 잘 전달되었는지 파악하기 힘듦.
- 중간에 메시징 시스템을 거치기 때문에 메시지 전달 속도가 빠르지 않음.
카프카의 메시지 시스템
- Publisher와 Subscriber로 이루어진 비동기 메시징 전송 방식

카프카의 아키텍처
- 프로듀서 (Producer)
- 메시지를 생산하여 브로커의 토픽으로 전달하는 역할
- 브로커 (Broker)
- 카프카 애플리케이션이 설치되어 있는 서버 또는 노드를 지칭
- 컨슈머 (Consumer)
- 브로커의 토픽으로부터 저장된 메시지를 전달 받는 역할
- 주키퍼 (Zookeeper)
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산된 노드의 정보를 중앙에 집중하고 구성 관리, 그룹 네이밍, 동기화 등의 서비스를 수행
작동 방식
- 프로듀서는 새 메시지를 카프카에 전달
- 전달된 메시지는 브로커의 토픽이라는 메시지 구분자에 저장
- 컨슈머는 구독한 토픽에 접근하여 메시지를 가져옴 (pull 방식)
기존 메시징 시스템과 다른 점
- 영속성 - 디스크에 메시지 저장
- 기존 메시징 시스템과 가장 큰 특징.
- 기존 메시징 시스템: Consumer가 메시지를 소비하면 큐에서 바로 메시지를 삭제.
- 카프카: Consumer가 메시지를 소비하더라도 디스크에 메시지를 일정 기간 보관.
- Multi-Producer, Multi-Consumer
- Producer와 Consumer 모두 하나 이상의 메시지를 주고 받을 수 있음.
- 분산형 스트리밍 플랫폼
- 단일 시스템 대비 성능이 우수.
- 시스템 확장이 용이함.
- 일부 노드가 죽더라도 다른 노드가 해당 일을 지속함. (고가용성)
- 페이지 캐시
- 잔여 메모리를 이용해 디스크 Read/Write를 하지 않고, 페이지 캐시를 통한 Read/Write를 인해 처리 속도가 매우 빠름.
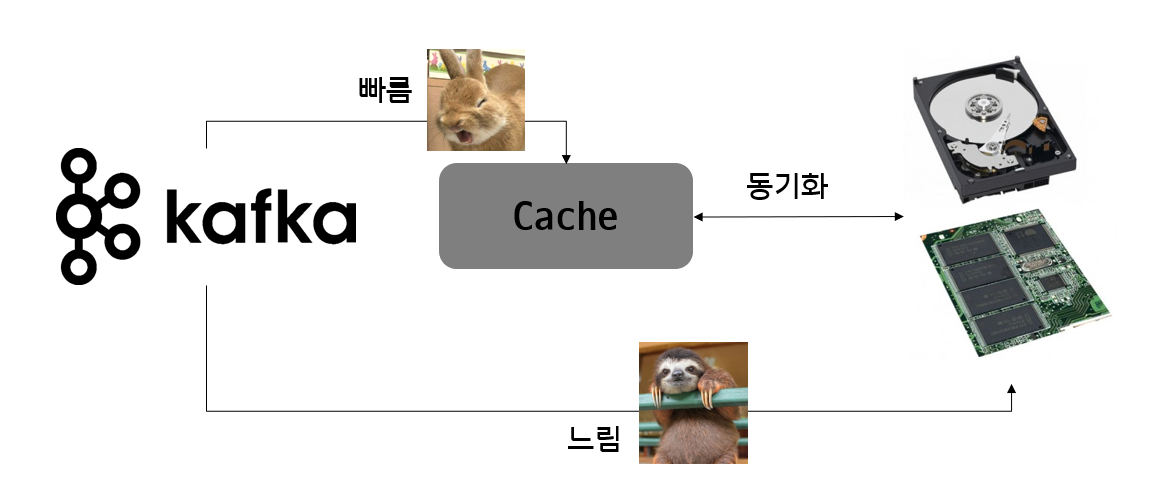
- 배치 전송 처리
- 메시지를 작은 단위로 묶어 배치 처리를 함으로써 속도 향상에 큰 도움을 줌.
다른 Pub/Sub 메시징 시스템과의 비교
- Kafka
- RabbitMQ
- Google Cloud Pub/Sub
⇒ 모두 비동기 통신을 제공하며, Producer와 Consumer가 분리되어 있음.
RabbitMQ
- AMQP를 위해 개발되어 다른 AMQP 프로토콜 기반 MQ 등과 데이터 교환이 수훨함.
- AMQP → Advanced Message Queuing Protocol, 클라이언트와 미들웨어 간 메시지 교환 개방형 표준 프로토콜

- 필요에 따라 동기/비동기 구현이 가능함.
- 유연한 라우팅이 가능하여 관리가 쉽고, 관리 UI가 직관적이고 편리함.
- exchanger가 메시지를 적절히 각각의 queue에 분배함.
- 브로커 중심적이며, 프로듀서와 메시지 간 메시지 전달 보장에 초점을 맞추어 신뢰성이 높음.
- 20k+/sec 처리 보장
처리 속도 비교
- Producer의 메시지 배치 처리 성능 비교

- Consumer 메시지 수신 처리 성능 비교

Kafka
- 높은 처리량 및 고성능/분산/스케일 아웃이 중요한 경우
- 가용성(장애 대응)이 높아야 하는 경우
- 메시지 전달 보장이 필수적이지 않은 경우
- 메시지 처리 순서가 보장되어야 하는 경우
- 스트리밍 데이터 처리가 필요한 경우
- 메시지 영속성이 필요한 경우
RabbitMQ
- 빠르고 쉽게 메시지 큐 시스템을 구축하고자 하는 경우 (라우팅 기능이 유연함)
- 메시지 전달 보장이 필수적인 경우
- 메시치 처리 순서가 보장되지 않아도 되는 경우
- 메시지 영속성 X
Google Pub/Sub
- Kafka와 유사한 아키텍처 (topic 개념)
- 클라우드 서비스로서 별도의 설치나 운영이 필요없음
- 메시지 처리 순서 보장이 안됨(분산형 아키텍처)
- 메시지 영속성 X (저장기간 최대 7일)
출처
- https://kerpect.tistory.com/63?category=874039
- https://kafka.apache.org/
- https://www.tibco.com/ko/reference-center/what-is-apache-kafka
- https://engineering.linecorp.com/ko/blog/how-to-use-kafka-in-line-1/
- https://velog.io/@jaehyeong/Apache-Kafka아파치-카프카란-무엇인가
- https://galid1.tistory.com/793
- https://m.blog.naver.com/neos_rtos/220937824768