

[JPQ] 객체 지향 쿼리 소개, JPQL
jpa-study에서 스터디를 진행하고 있습니다.
객체지향 쿼리 소개
JPQL 소개
- JPQL(Java Persistence Query Language)은 엔티티 객체를 조회하는 객체지향 쿼리다.
- JPQL은 SQL을 추상화하여 특정 데이터베이스에 의존하지 않는다.
- 데이터베이스 방언이 바뀌어도 JPQL을 수정하지 않아도 된다.
- JPQL은 SQL보다 코드가 간결하다.
"select m from Member as m where m.username = 'kim'"
- JPQL은 결국 SQL로 변환된다.
Criteria 쿼리 소개
- Criteria는 JPQL을 생성하는 빌더 클래스이다.
- Criteria는 문자가 아닌 프로그래밍 코드로 JPQL을 작성할 수 있다.
- 가령 JPQL에서
select m from Membeeee m처럼 오타가 나면 컴파일 시점에서 성공하고, 런타임 시점에서 실제로 사용이 되어야 예외가 발생한다. - 그래서 Criteria는 아래와 같은 장점이 있다.
- 컴파일 시점에서 오류 발견 가능.
- IDE를 사용하면 코드 자동 완성.
- 동적 쿼리를 작성하기 편함.
- 가령 JPQL에서
// Criteria 사용 준비
CriteriaBuilder cb = eb.getCriteriaBuilder();
CriteriaQuery<Member> query = cb.createQuery(Member.class);
// 루트 클래스 (조회를 시작할 클래스)
Root<Member> m = query.from(Member.class);
// 쿼리 생성
CriteriaQuery<member> cq = query.select(m).where(cb.equal(m.get("username"), "kim"));
List<Member> resultList = em.createQuery(eq).getResultList();
- 위와 같이 예제 코드를 작성할 수 있는데, 굉장히 복잡하고 장황하다. 따라서 최근에 Criteria는 거의 사용하지 않는다.
QueryDSL 소개
- QueryDSL도 Criteria처럼 JPQL 빌더 역할을 한다.
- QueryDSL은 오픈 소스 프로젝트로, JPA 외에 JDO, 몽고DB 등도 거의 같은 문법으로 지원하며, Criteria보다 이를 많이 사용하는 추세이다.
// 준비
JPAQuery query = new JPAQuery(em);
QMember member = QMember.member;
// 쿼리, 결과 조회
List<Member> members =
query.from(member)
.where(member.username.eq("kim"))
.list(member);
- QMember는 Member 엔티티 클래스를 기반으로 생성한 QueryDSL 쿼리 전용 클래스이다.
네이티브 SQL 소개
- JPQL을 사용해도 가끔 특정 데이터베이스에 의존하는 기능을 사용할 때가 있다.
- 오라클 데이터베이스만 제공하는 CONNECT BY 기능이나 특정 데이터베이스에서만 동작하는 SQL 힌트 등이 있다.
- 즉, JPQL에서 지원하지 않는 쿼리를 써야 할 경우 네이티브 SQL을 사용한다.
"SELECT ID, AGE, TEAM_ID, NAME FROM MEMBER WHERE NAME = 'kim'"
JDBC 직접 사용, Mybatis 같은 SQL 매퍼 프레임워크 사용
- JPA의 EntityManager에서 하이버네이트 Session을 구하고, Session의
doWork()를 호출하면 JDBC 커넥션을 획득할 수 있다. - JDBC 커넥션에 직접 접근하고 싶을 때 사용하나, 거의 그럴 일이 없다.
JPQL
기본 문법과 쿼리 API
SELECT문
SELECT m FROM Member AS m where m.username = 'Hello'
- 대소문자 구분
- 엔티티와 속성은 대소문자를 구분한다. 예를 들어, Member와 username은 대소문자를 구분한다.
- SELECT, FROM, AS 같은 JPQL 키워드는 대소문자를 구분하지 않는다.
- 엔티티 이름
- JPQL에서 사용한 Member는 클래스 명이 아니라 엔티티 명이다. 기본 값인 클래스 명을 엔티티 명으로 사용하는 것을 추천한다.
@Entity(name="XXX")로 엔티티 명을 수정하면 혼선을 빚을 수 있다.
- 별칭은 필수
m과 같은 별칭을 필수로 사용해야 하며, AS는 생략이 가능하다.
TypeQuery, Query
- JPQL을 실행하려면 쿼리 객체를 만들어야 하는데, 반환할 타입을 지정할 수 있으면 TypeQuery 객체를 사용하고 그렇지 않으면 Query 객체를 사용한다.
TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
List<Member> resultList = query.getResultList();
Query query = em.createQuery("SELECT m FROM Member m");
List resultList2 = query.getResultList();
for (Object o : resultList) {
Object[] result = (Object[]) o; // 결과가 둘 이상이면 Object[] 반환
}
em.createQuery()의 두 번째 파라미터에 반환할 타입을 지정하면 TypeQuery를 반환하고 지정하지 않으면 Query를 반환한다.- Query 객체는 SELECT 절의 조회 대상이 여러 개이면
Object[]를 반환한다.SELECT m.username, m.age FROM Member m
- 따라서 타입을 변환할 필요가 없는 TypeQuery를 사용하는 것을 추천한다.
결과 조회
query.getResultList(): 결과를 컬렉션으로 반환하며, 결과가 없으면 빈 컬렉션을 반환한다.query.getSingleResult(): 결과가 정확히 하나일 때 사용할 수 있으며, 그렇지 않으면 예외가 발생한다. 컬렉션이 아닌, 객체 하나를 반환한다.
파라미터 바인딩
이름 기준 파라미터
- 파라미터를 이름으로 구분하는 방법이다.
- 앞에
:를 사용한다.
String usernameParam = "User1";
List<member> resultList =
em.createQuery("SELECT m FROM Member m WHERE m.username = :username", Member.class);
.setParameter("username", usernameParam)
.getResultList();
위치 기준 파라미터
?다음에 위치 값을 주면 되며, 위치 값은 1부터 시작한다.
List<member> resultList =
em.createQuery("SELECT m FROM Member m WHERE m.username = ?1", Member.class);
.setParameter(1, usernameParam)
.getResultList();
참고로, 파라미터 바인딩을 사용하지 않고 + 연산을 사용하여 쿼리 문자열을 이어 붙이면 SQL 인젝션 공격을 받을 수 있고, 성능 상으로도 좋지 않으니 파라미터 바인딩을 필수로 사용하자.
프로젝션
- SELECT 절에 조회 할 대상을 지정하는 것을 프로젝션이라 한다.
SELECT (프로젝션 대상) FROM- 프로젝션 대상은 엔티티, 임베디드 타입, 스칼라 타입이 있다.
- 스칼라 타입은 기본 데이터 타입을 뜻함.
엔티티 프로젝션
SELECT m FROM Member m // 회원
SELECT m.team FROM Member m // 팀
- 참고로 이렇게 조회한 엔티티는 영속성 컨텍스트에서 관리된다.
임베디드 타입 프로젝션
- 임베디드 타입은 엔티티와 거의 비슷하게 사용되나, 조회의 시작점이 될 수 없다.
SELECT a FROM Address a- 위 코드에서 Address는 임베디드 타입이다.
- 대신 엔티티를 통해서 임베디드 타입을 조회할 수 있가.
SELECT o.address FROM Order o
- 임베디드 타입은 값 타입이므로 영속성 컨텍스트에서 관리되지 않는다.
스칼라 타입 프로젝션
- 일반적으로 사용하는 쿼리문이다.
SELECT username FROM Member m
여러 값 조회
- 프로젝션에서 여러 값을 선택하면 Query를 사용해야 한다. 그러나 여러 프로젝션을 처리하기 위해
Object[]를 사용하여 적절한 객체로 변환하는 일은 바람직하지 않다. - 그래서 여러 값으로 구성된 객체를 따로 설계하고, 그 객체를 JPQL 단에서 생성하여 반환함으로써 TypedQuery를 사용한다. 자세한 예시를 살펴 보자.
public class UserDTO {
private String username;
private int age;
// 생성자
}
TypedQuery<UserDTO> query =
em.createQuery("SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m",
UserDTO.class);
List<UserDTO> resultList = query.getResultList();
- SELECT 다음에 NEW 명령어를 사용하면 반환 받을 클래스를 지정할 수 있는데 이 클래스의 생성자에 JPQL 조회 결과를 넘겨 줄 수 있다.
- NEW 명령어를 사용할 때는 2가지를 주의해야 한다.
- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다.
- 순서와 타입이 일치하는 생성자가 필요하다.
페이징 API
JPA는 페이징을 다음 두 API로 추상화하였다.
setFirstResult(int startPosition): 조회 시작 위치(0부터 시작)setMaxResults(int maxResult): 조회할 데이터 수
TypedQuery<Member> query = "..."
query.setFirstResult(10); // 11번부터 시작
query.setMaxResults(20); // 11번 ~ 30번 데이터 조회
query.getResultList();
집합과 정렬
집합 함수
- 집합 함수는 COUNT, MAX, MIN, AVG, SUM이 있다.
- 주의 사항은 다음과 같다.
- NULL 값은 무시한다.
- 값이 없는데 집합 함수를 사용하면 NULL이 된다. 단, COUNT는 0.
- DISTINCT를 집합 함수 안에 사용해서 중복된 값을 걸러내고 집합을 구할 수 있다.
- DISTINCT를 COUNT에서 사용할 때 임베디드 타입은 지원하지 않는다.
GROUP BY, HAVING
- GROUP BY는 통계 데이터를 구할 때 특정 그룹끼리 묶어 준다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
from Member m LEFT JOIN m.team t
GROUP BY t.name
- 위 코드는 팀 이름을 기준으로 그룹 별로 묶어서 통계 데이터를 구하고 있다.
- 만약 그룹별 통계 데이터 중에서 평균 나이가 10살 이상인 그룹을 조회하고 싶으면 다음과 같이 코드를 작성할 수 있다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
from Member m LEFT JOIN m.team t
GROUP BY t.name
HAVING AVG(m.age) .= 10
정렬
- ORDER BY를 사용하며, ASC는 오름차순, DESC는 내림차순 정렬을 뜻한다.
select m from Member m order by m.age DESC, m.username ASC
JPQL 조인
내부 조인
- INNER는 생략하고 JOIN만 써도 된다.
SELECT m
FROM Member m INNER JOIN m.team t
where t.name = :teamName
- JPQL 조인의 가장 큰 특징은 연관 필드를 사용한다는 것이다.
- 연관 필드: 다른 엔티티와 연관 관계를 가지기 위해 사용하는 필드
FROM Member m INNER JOIN Team t과 같이 일반 SQL 문법을 사용하면 오류가 발생한다.
외부 조인
- OUTER를 생략하고 LEFT JOIN만 써도 된다.
SELECT m
FROM Member m LEFT JOIN m.team t
컬렉션 조인
- 일대다 관계나 다대다 관계처럼 컬렉션을 사용하는 곳에 조인하는 것을 컬렉션 조인이라 한다.
- [회원 → 팀] 조인은 단일 값 연관 필드를 사용하고, [팀 → 회원] 조인은 컬렉션 값 연관 필드를 사용한다.
SELECT t, m
FROM Team t LEFT JOIN t.members m
세타 조인
- WHERE 절을 사용해서 세타 조인을 할 수 있다. (세타 조인은 내부 조인만 가능)
select count(m) from Member m, Team t
where m.username = t.name
JOIN ON 절
- JPA 2.1부터 조인할 때 ON 절을 지원한다.
- ON 절을 사용하면 조인 대상을 필터링하고 조인할 수 있다.
- 참고로 내부 조인의 ON 절은 WHERE 절을 사용할 때와 결과가 같으므로 보통 ON 절은 외부 조인에서만 사용한다.
select m, t from Member m
left join m.team t on t.name = 'A'
페치 조인
- 페치 조인은 SQL에서 말하는 조인의 종류는 아니고, JPQL에서 성능 최적화를 위해 제공하는 기능이다.
- 연관된 엔티티나 컬렉션을 한 번에 같이 조회할 수 있다.
join fetch
엔티티 페치 조인
// JPQL
select m
from Member m join fetch m.team
// SQL
SELECT M.*, T.*
FROM MEMBER T
INNER JOIN TEAM T ON M.TEAM_ID = T.ID
- 페치 조인을 이용하면 회원 엔티티를 조회하면서 연관된 팀 엔티티도 함께 조회할 수 있다.
- 참고로
m.team다음에 별칭이 없는데, 페치 조인은 별칭을 사용할 수 없다.- 하이버네이트는 페치 조인에도 별칭을 허용한다.
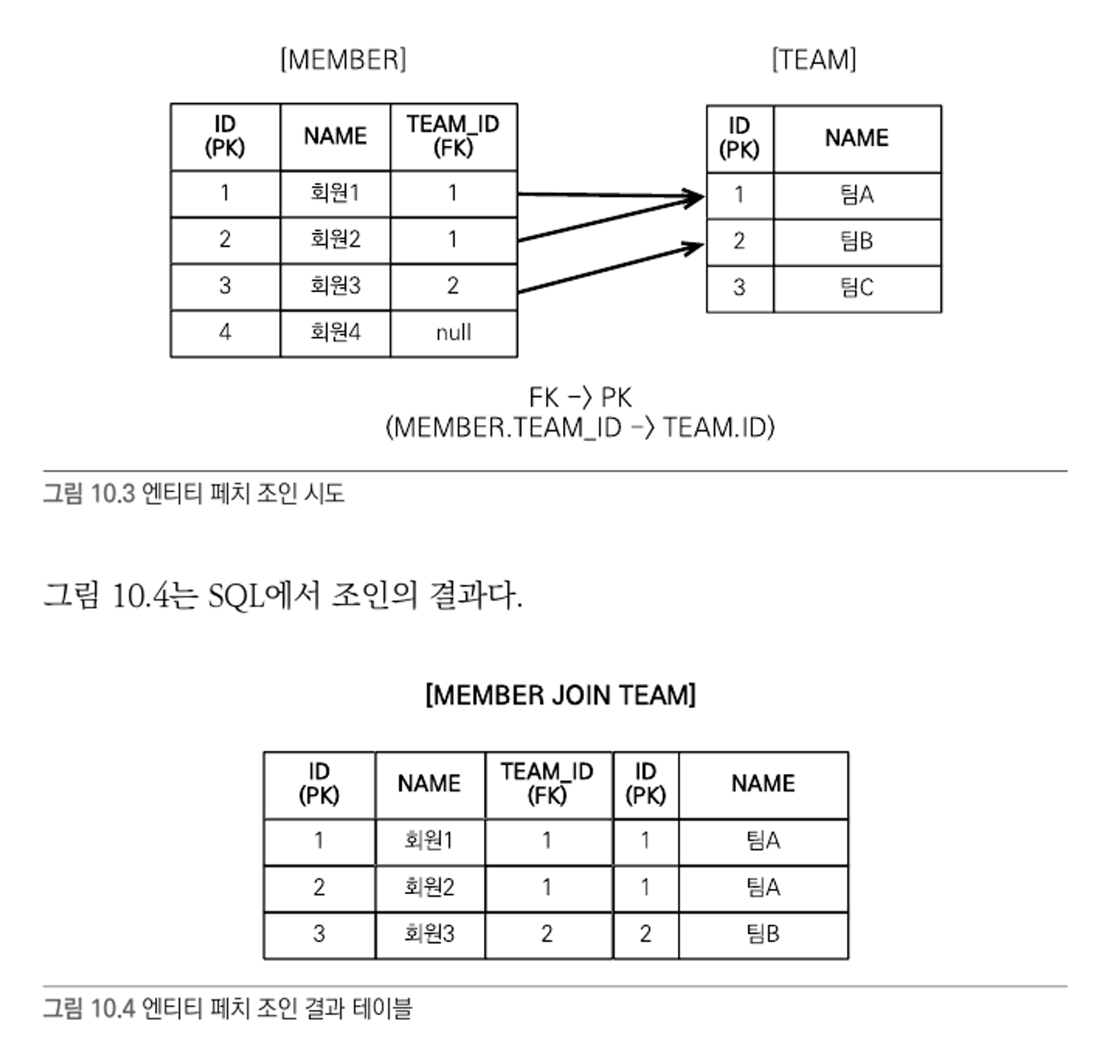
- 엔티티 페치 조인 SQL에서 회원과 연관된 팀을 모두 조회하는 것을 알 수 있다.
- 회원 1과 회원 2는 팀 A를, 회원 3은 팀 B와 연관 관계를 맺게 되었다.
- 회원과 팀을 지연 로딩으로 설정해도 페치 조인을 사용하면 즉시 로딩이 된다.
컬렉션 페치 조인
- 이번에는 일대다 관계인 컬렉션을 페치 조인해 보자.
// JPQL
select t
from Team t join fetch t.members
where t.name = '팀A'
// SQL
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M ON T.ID = M.TEAM_ID
WHERE T.NAME = '팀A'
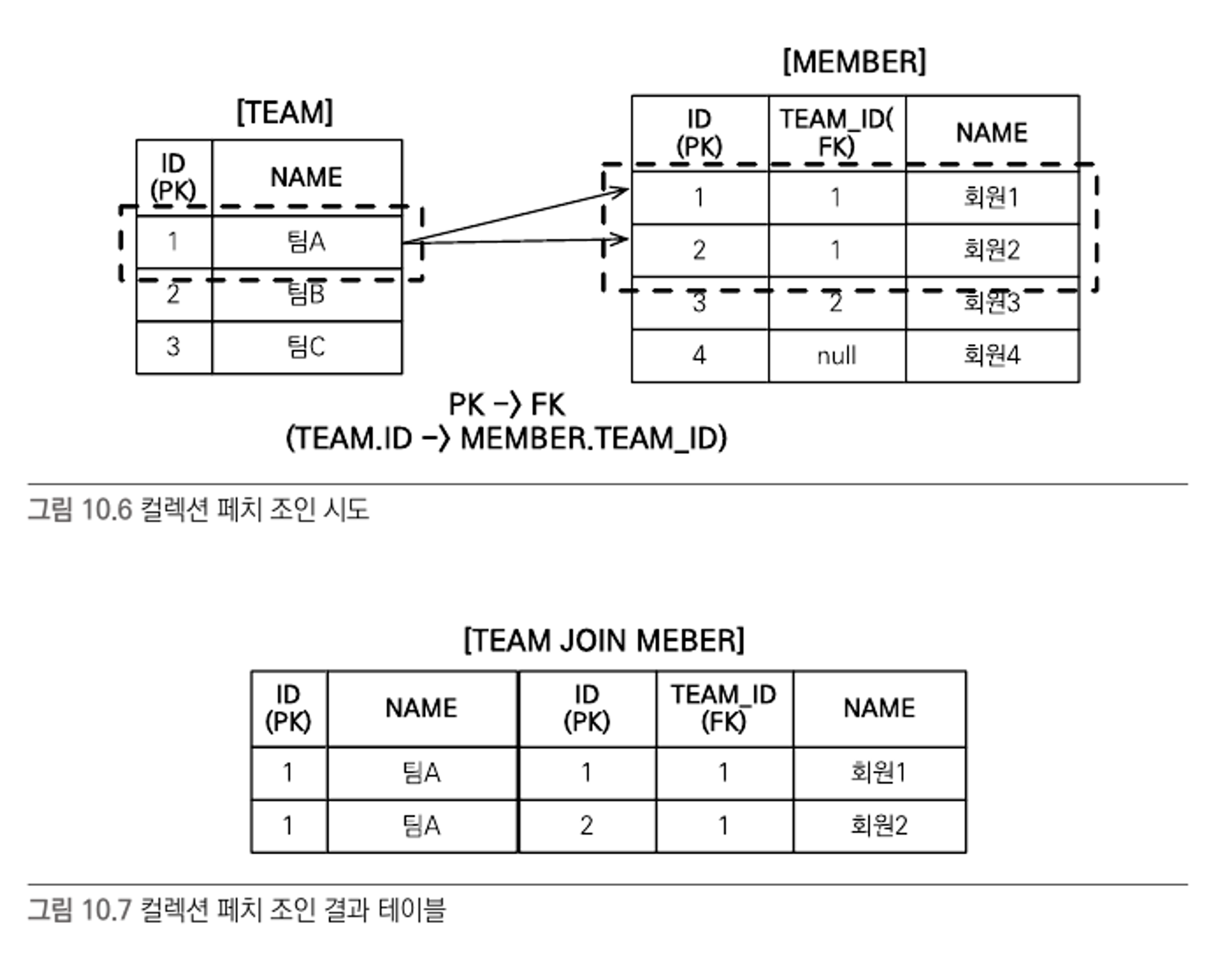
- 엔티티 페치 조인처럼 팀과 연관된 회원을 모두 조회한 것을 알 수 있다.
- 문제는 TEAM 테이블에서 ‘팀A’는 하나지만 MEMBER 테이블과 조인하면서 결과가 증가하여 ‘팀A’가 2건 조회된 것을 알 수 있다.
- 따라서 컬렉션 페치 조인 결과 객체인
Teams는 동일한 주소를 가진 ‘팀A’ 2건을 가지게 된다.
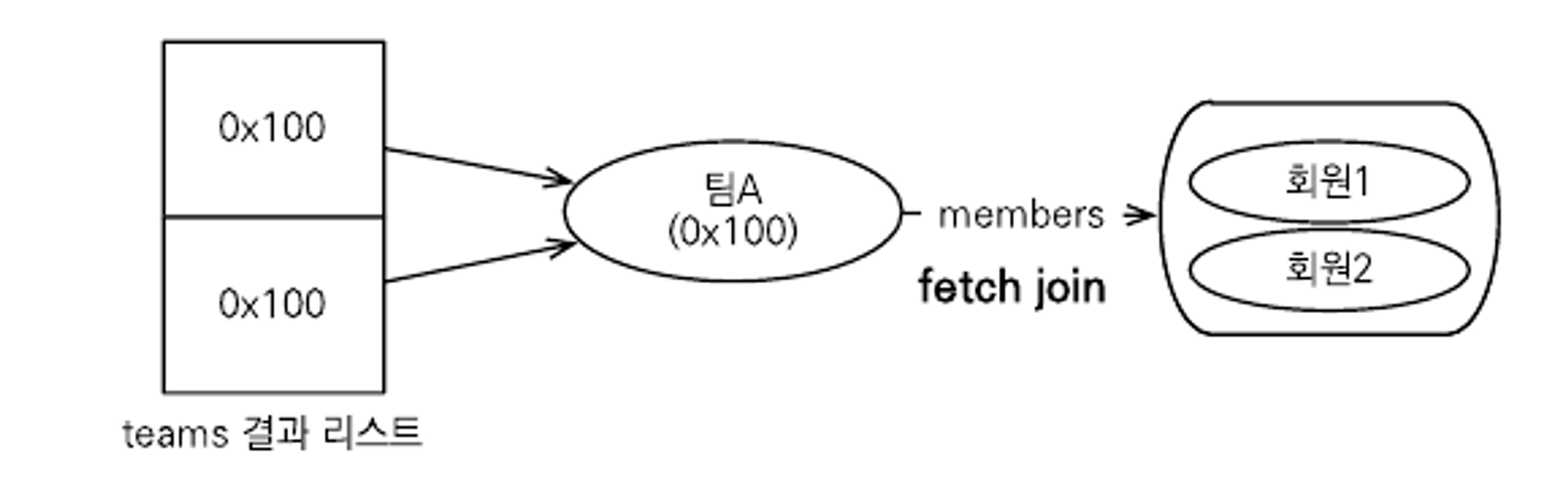
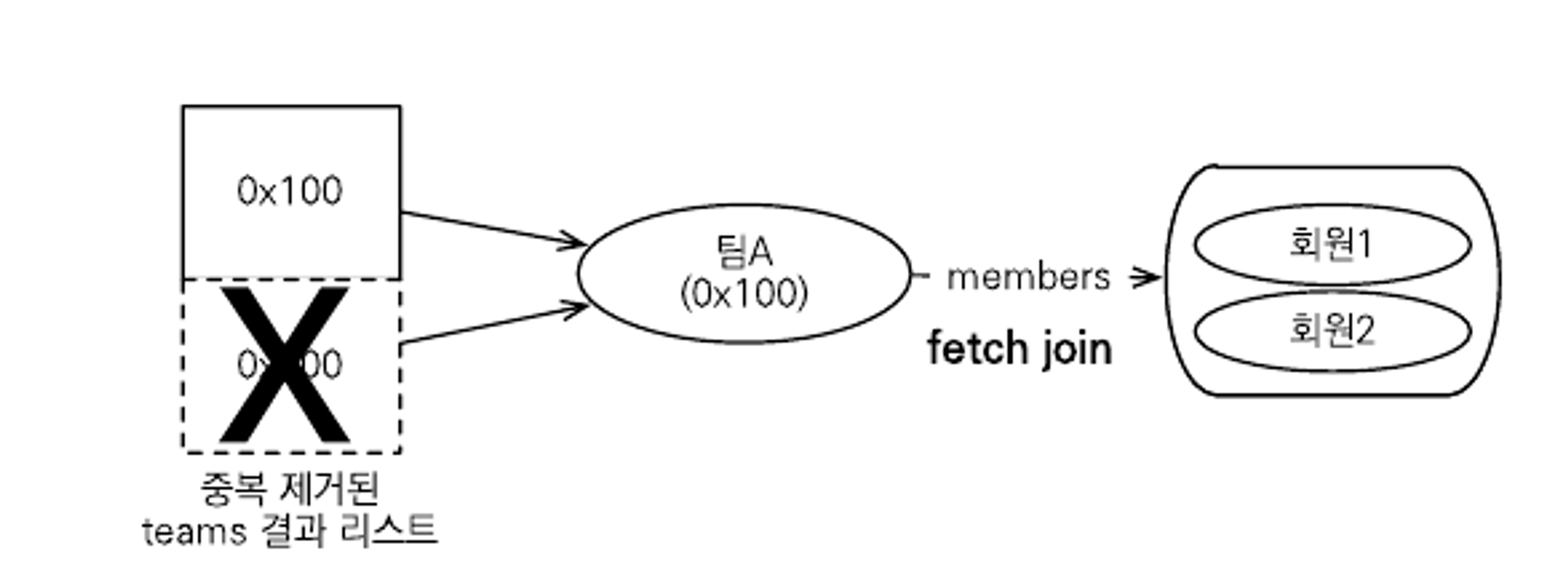
페치 조인과 DISTINCT
- JPQL의 DISTINCT 명령어는 SQL에 DISTINCT를 추가하고, 애플리케이션에서 한 번 더 중복을 제거한다.
- 위 예시에서 각 row의 데이터가 다르므로 SQL의 DISTINCT는 효과가 없으나 애플리케이션에서는 엔티티의 중복을 제거할 수 있다. 이것은 참조된 주소를 보고 판단한 것이다.
페치 조인과 일반 조인의 차이
- 페치 조인을 사용하지 않고 조인만 사용하면 결과를 반환할 때 연관관계를 고려하지 않고, 단순히 SELECT절에 지정한 엔티티만 조회한다.
- 가령 다음과 같은 JPQL을 실행했을 때 팀과 회원 컬렉션을 조인했으니 회원 엔티티도 조회 되어야 하는데 실상은 그렇지 않다.
select t
from Team t join t.members m
where t.name = '팀A'
- 만약 즉시 로딩으로 설정하면 회원 컬렉션을 즉시 로딩하기 위해 쿼리를 한 번더 실행한다.
- 반면에 페치 조인을 사용하면 지연 로딩이든 즉시 로딩이든 상관 없이 연관된 엔티티를 함께 조회한다.
페치 조인의 특징과 한계
- 엔티티에 직접 적용하는 로딩 전략은 애플리케이션 전체에 영향을 미치므로 글로벌 로딩 전략이라 부른다.
- 페치 조인은 글로벌 로딩 전략보다 우선적으로 실행한다. 그래서 지연 로딩으로 설정하더라도 JPQL에서 페치 조인을 사용하면 페치 조인을 적용하게 된다.
- 글로벌 로딩 전략은 지연 로딩을 사용하고, 최적화가 필요하면 페치 조인을 적용하는 것이 좋다.
- 페치 조인의 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.
- 둘 이상의 컬렉션을 페치할 수 없다.
- 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다.
- 단일 값 연관 필드는 페치 조인을 사용해도 페이징 API를 사용할 수 있다.
경로 표현식
- 경로 표현식은
.을 찍어 객체 그래프를 탐색하는 것이다.
경로 표현식의 용어 정리
- 상태 필드: 단순히 값을 저장하기 위한 필드(필드 or 프로퍼티)
- 연관 필드: 연관 관계를 위한 필드 (임베디드 타입 포함)
- 단일 값 연관 필드: @ManyToOne, @OneToOne 대상 엔티티
- 컬렉션 값 연관 필드: @OneToMany, @ManyToMany 대상 컬렉션
경로 표현식과 특징
- 상태 필드 경로: 경로 탐색의 끝이므로 더 탐색할 수 없다.
- 단일 값 연관 경로: 묵시적으로 내부 조인이 일어나며, 계속 탐색할 수 있다.
select o.member from Order o- SQL에서 내부 조인이 일어난다. 이를 묵시적 조인이라고 하며, 묵시적 조인은 모두 내부 조인이므로 외부 조인을 사용하고 싶으면 명시적 조인을 사용해야 한다.
- 컬렉션 값 연관 경로: 묵시적으로 내부 조인이 일어나며, 더 탐색할 수 없다. 단 FROM 절에서 조인을 통해 별칭을 얻으면 별칭으로 탐색할 수 있다.
select t.members from Team t- SQL에서 내부 조인이 일어난다. 다만,
t.members.username처럼 경로 탐색을 이어서 할 수 없다. select t.members from Team t join t.members m과 같이 명시적 조인을 통해 새로운 별칭을 획득했다면 별칭을 통해 이어서 탐색이 가능하다.
경로 탐색을 사용한 묵시적 조인 시
- 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어렵기 때문에 명시적 조인을 사용하는 것이 바람직하다.
서브 쿼리
- JPQL에서 서브 쿼리는 WHERE, HAVING 절에만 사용할 수 있다.
- EXISTS, ALL, ANY, SOME, IN 함수를 사용하면 된다.
조건식
타입 표현
- 문자, 숫자, 날짜, Boolean, Enum, 엔티티 타입이 있다.
연산자 우선 순위
- 경로 탐색 연산
- 수학 연산: +, -(단항 연산자), *, /, +, -
- 비교 연산: =, >, ≥, <, ≤, <>, BETWEEN, LIKE, IN, IS NULL, IS EMPTY, MEMBER, EXISTS
- 논리 연산: NOT, AND, OR
컬렉션 식
- 빈 컬렉션 비교식
{컬렉션 값 연관 경로} IS EMPTY- 컬렉션에 값이 비었으면 참
// 주문이 하나라도 있는 회원 조회
select m from Member m
where m.orders is not empty
- 컬렉션의 멤버 식
{엔티티나 값} MEMBER {컬렉션 값 연관 경로}- 엔티티나 값이 컬렉션에 포함되어 있으면 참
select t from Team t
where :memberParam member of t.members
스칼라 식
- 스칼라는 숫자, 문자, 날짜, case, 엔티티 타입같은 가장 기본적인 타입이다.
- 스칼라 타입에 사용하는 식은 수학 식, 문자 함수, 날짜 함수, CASE가 있다.
CASE 식
- 위에서 언급한 스칼라 식 중 하나로, 특정 조건에 따라 분기할 때 사용한다.
[기본 CASE]
CASE
{WHEN <조건식> THEN <스칼라 식>}+
ELASE <스칼라식>
END
[심플 CASE]
CASE <조건 대상>
{WHEN <스칼라식1> THEN <스칼라식2>}+
ELSE <스칼라식>
END
[COALESCE]
- 문법:
COALESCE(<스칼라식> {, <스칼라식>}+) - 스칼라 식을 차례대로 조회하여 null이 아니면 반환한다.
// m.username이 null이면 '이름 없는 회원'을 반환하라.
select coalesce(m.username, '이름 없는 회원') from Member m
[NULLIF]
- 문법:
NULLIF(<스칼라식>, <스칼라식>) - 두 값이 같으면 null을 반환하고 다르면 첫 번째 값을 반환한다. 집합 함수는 null을 포함하지 않으므로 보통 집합 함수와 함께 사용한다.
// 사용자 이름이 '관리자'면 null을 반환하고, 나머지는 본인의 이름을 반환하라.
select NULLIF(m.username, '관리자') from Member m
다형성 쿼리
- JPQL로 부모 엔티티를 조회하면 그 자식 엔티티도 함께 조회한다.
TYPE
- 엔티티의 상속 구조에서 조회 대상을 특정 자식 타입으로 한정한다.
select i from Item i
where type(i) IN (Book, Movie)
TREAT
- 자바의 타입 캐스팅과 유사하여 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용한다.
select i from Item i where treat(i as Book).author = 'kim'
사용자 정의 함수 호출
- 사용할 데이터베이스 함수를 미리 persistence.xml에 등록하고, 아래 문법으로 사용하면 된다.
function_invocation::=FUNCTION(function_name {, function_arg}*)
엔티티 직접 사용
기본 키 값
- 객체 인스턴스는 참조 값으로 식별하고, 테이블 row는 기본 키 값으로 식별한다.
- 따라서 JPQL에서 엔티티 객체를 직접 사용하면 SQL에서는 해당 엔티티의 기본 값을 사용한다.
// JPQL
select count(m) from Member m
// SQL
select count(m.id) as cnt from Member m
외래 키 값
Team team = em.find(Team.class, 1L);
String query = "select m from Member m where m.team = :team";
List resultList = em.createQuery(query)
.setParameter("team", team)
.getResultList();
기본 키 값이 1L인 팀 엔티티를 파라미터로 사용하고 있다. m.team 은 현재 team_id 라는 외래 키와 매핑되어 있다. 따라서 다음과 같은 SQL이 실행된다.
select m.*
from Member m
where m.team_id=? (팀 파라미터의 ID 값)
그래서 엔티티 대신 식별자 값을 파라미터로 줄 수도 있다.
String query = "select m from Member m where m.team.id = :teamId";
List resultList = em.createQuery(query)
.setParameter("teamId", 1L)
.getResultList();
참고로, m.team.id 를 보면 Member와 Team 간에 묵시적 조인이 일어날 것 같지만 Member 테이블이 team_id 외래 키를 가지고 있으므로 묵시적 조인은 일어나지 않는다. 물론 m.team.name 을 호출하면 묵시적 조인이 일어난다.
Named 쿼리: 정적 쿼리
- 동적 쿼리:
em.createQuery()처럼 JPQL을 문자로 완성해서 직접 넘기는 쿼리이다. 런타임에 따라 특정 조건에 따라 JPQL을 동적으로 구성할 수 있다. - 정적 쿼리: 미리 정의한 쿼리에 이름을 부여해서 필요할 때 재사용할 수 있고, 이를 Named 쿼리라 부른다. Named 쿼리는 한 번 정의하면 변경할 수 없다.
Named 쿼리를 어노테이션에 정의
@Entity
@NamedQuery(
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username")
public class Member {
}
위와 같이 세팅을 하고, 다음과 같이 사용해 보자.
List<Member> result List =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();
Named 쿼리를 XML에 정의
자바 언어로 멀티 라인 문자를 다루는 것은 상당히 귀찮은 일이므로 그나마 나은 XML에 정의를 할 수 있다.
출처
김영한 - 자바 ORM 표준 JPA 프로그래밍
'스터디 > JPA 스터디' 카테고리의 다른 글
| [JPA] 스프링 데이터 JPA (0) | 2022.02.05 |
|---|---|
| [JPA] QueryDSL, 네이티브 SQL, 객체지향 쿼리 심화 (1) | 2022.01.30 |
| [JPA] Qna 미션을 통해 새롭게 배운 내용 정리 (0) | 2022.01.17 |
| [JPA] 값 타입 (0) | 2022.01.01 |
| [JPA] 프록시와 연관 관계 관리 (0) | 2021.12.25 |
댓글