

[Java] atomic과 CAS 알고리즘
java-study에서 스터디를 진행하고 있습니다.
synchronized의 문제점
synchronized는 blocking을사용하여 멀티 스레드 환경에서 공유 객체를 동기화하는 키워드이다. 그러나 blocking에는 여러 가지 단점이 존재하는데, 그 중에서 손 꼽는 문제는 성능 이슈이다.
특정 스레드가 해당 블럭 전체에 lock을 걸면, 해당 lock에 접근하는 스레드들은 블로킹 상태에 들어가기 때문에 아무 작업도 하지 못한 채 자원을 낭비한다. 또한 blocking 상태의 스레드를 준비 혹은 실행 상태로 변경하기 위해 시스템의 자원을 사용해야 한다. 결국 이 문제는 성능 저하로 이어진다.
예를 들어 자동차 운전을 한다고 가정해 보자. 운전자가 방향 전환을 하려고 하는데, 마침 앞에 다른 자동차가 대기하고 있다. 운전자는 앞의 차가 먼저 지나가기를 기다리기 위해 정차를 하고, 앞의 차가 지나가면 다시 출발을 해야 한다. 이처럼 자동차를 정차하고 다시 출발하고, 앞의 차를 기다리며 많은 에너지가 소비되는 것과 비슷한 이치이다.
이러한 문제점 때문에 non-blocking을 하며 원자성을 보장하기 위한 방법이 atomic 변수이다.
원자성과 Atomic Type
atomic 변수는 멀티 스레드 환경에서 원자성을 보장하기 위해 나온 개념이다. synchronized와는 다르게 blocking이 아닌 non-blocking하면서 원자성을 보장하여 동기화 문제를 해결한다.
atomic의 핵심 동작 원리는 CAS(Compare And Swap) 알고리즘이다.
CAS (Compare And Swap) 알고리즘
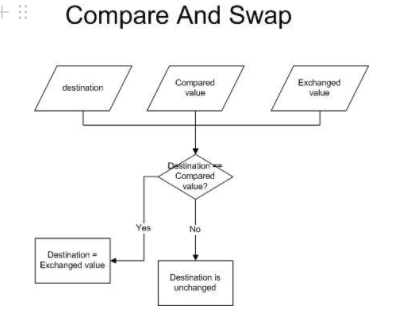
CAS 알고리즘의 동작 원리는 다음과 같다.
- 인자로 기존 값(Compared Value)과 변경할 값(Exchanged Value)을 전달한다.
- 기존 값(Compared Value)이 현재 메모리가 가지고 있는 값(Destination)과 같다면 변경할 값(Exchanged Value)을 반영하며 true를 반환한다.
- 반대로 기존 값(Compared Value)이 현재 메모리가 가지고 있는 값(Destination)과 다르다면 값을 반영하지 않고 false를 반환한다.
여기서 ‘기존 값으로 던진 값이 현재 메모리가 가지고 있는 값과 다른 경우가 뭐지?’라는 의문이 생길 수 있다. 이 말의 의미는 스레드 A가 공유 변수에 대해 계산을 하고, 메모리에 반영하기 직전에 다른 스레드 B가 공유 변수를 변경하여 메모리에 반영한 경우를 의미한다. 이때 당연히 스레드 A의 변경할 값을 메모리에 반영하면 안 된다.
따라서 false를 반환하는 경우에는 무한 루프를 구성하여 변경된 값(다른 스레드에 의해 변경된 메모리 값)을 읽고 같은 시도를 반복하거나, 다른 더 중요한 작업이 있으면 다른 작업을 해도 된다. 이 부분은 개발자가 결정한다.
정리하자면, atomic은 blocking 방식을 사용하는 synchronized에 비해 훨씬 효율적인 방법이라고 할 수 있다. 무한 루프를 돌면서 값을 반영할 수 있는지 물어보는 경우에도 스레드의 상태를 변경하는 작업이 발생하지 않으므로 성능이 더 우수하다.
Java에서의 CAS 동작 예시

위 그림은 JVM 내의 스레드 스케줄러에 의해 각각의 core에 스레드-1과 스레드-2가 선점된 상태이고, 두 스레드는 각각 for문에서 공유 변수 count를 증가시킨다고 가정한다.
- 각 스레드는 힙 내에 있는 count 변수를 읽어 CPU 캐시 메모리에 저장한다.
- 각 스레드는 번갈아가며 for문을 돌면서 count 값을 1씩 증가시킨다.
- 스레드-1 또는 스레드-2는 변경한 count 값을 힙에 반영하기 위해 변경하기 전의 count 값과 힙에 저장된 count 값을 비교한다. 여기서 이후 상황이 두 가지로 나뉜다.
- 변경하기 전의 count 값과 힙에 저장된 count 값이 다를 경우 false를 반환하며, 힙에 저장된 값을 읽어 2번 과정으로 돌아간다.
- 변경하기 전의 count 값과 힙에 저장된 count 값이 같을 경우 true를 반환하며, 힙에 변경한 값을 저장한다.
- 힙에 변경한 값을 저장한 스레드-1 또는 스레드-2는 1번 과정으로 돌아간다. (for문이 종료될 때까지)
정리
atomic 변수의 핵심 원리인 CAS 알고리즘은 원자성 뿐만 아니라 가시성 문제도 해결해 주는 것을 볼 수 있다. 그리고 non-blocking이 가능하므로 blocking 방식인 synchronized보다 성능 상 이점이 있다는 것도 알 수 있었다. 참고로 synchronized 키워드의 경우 synchronized 블록에 진입하기 전에 CPU 캐시 메모리와 메인 메모리 값을 동기화하여 가시성을 해결한다.
blocking에 관한 오해
필자는 synchronized 방식이 무한 루프를 돌면서 true를 반환할 때까지 기다리는 atomic 방식보다 성능이 우수하지 않나 생각을 했었다. 왜냐하면 blocking된 스레드는 즉시 자신이 CPU 제어권을 다른 스레드에게 양보하는 반면, non-blocking된 스레드는 무한 루프를 돌면서 의미 없이 true를 반환받을 때까지 CPU를 붙잡고 있기 때문이다.
하지만 싱글 코어 환경에서 공유 변수 count를 사용하는 스레드가 100개가 있다면 어떨까? synchronized 방식의 경우 blocking이므로 count를 사용하는 하나의 스레드 외에 나머지는 모두 스레드 상태가 blocked로 바뀌고 다른 일을 할 수 없다. 따라서 CPU 자원이 낭비가 되고, 공유 자원의 lock이 풀리더라도 특정 스레드의 상태를 blocked에서 running으로 바꾸어야 하고, 반대로 99개의 스레드를 running에서 blocked 상태로 바꾸어야 하므로 atomic에 비해 성능이 느릴 수 밖에 없다.
반면 atomic 방식의 경우 non-blocking이므로 비록 무의미한 무한 루프를 돌 수도 있지만, true를 반환 받는 순간 스레드의 상태를 변경하는 일 없이 바로 이후 작업을 이어서 할 수 있다. 또한, non-blocking 방식은 무한 루프를 하면서 작업이 끝났는지 물어보지 않고 다른 작업을 해도 되므로 선택이 자유롭다.
AtomicInteger 살펴 보기
atomic type인 AtomicInteger 클래스가 동기화 문제를 어떻게 해결하는지 살펴 보자.
public class AtomicIntegerTest {
private static int count;
public static void main(String[] args) throws InterruptedException {
AtomicInteger atomicCount = new AtomicInteger(0);
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
count++;
atomicCount.incrementAndGet();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
count++;
atomicCount.incrementAndGet();
}
});
thread1.start();
thread2.start();
Thread.sleep(5000);
System.out.println("atomic 결과 : " + atomicCount.get());
System.out.println("int 결과 : " + count);
}
}
AtomicInteger와 int 타입인 count 변수를 생성한 다음, 두 개의 스레드에서 count++ 연산을 하는 예제이다. 결과는 다음과 같다.
//결과
atomic 결과 : 200000
int 결과 : 152298
AtomicInteger 타입인 atomicCount는 의도 대로 200000이 출력되는 것을 볼 수 있고, int 타입인 count는 동기화가 지켜지지 않아 잘못된 값을 출력하는 것을 볼 수 있다.
동기화가 어떻게 지켜지는지 AtomicInteger 클래스의 incrementAndGet() 메소드를 살펴 보자.
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe U = Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
private volatile int value;
public final int incrementAndGet() {
return U.getAndAddInt(this, VALUE, 1) + 1;
}
}
public final class Unsafe {
@HotSpotIntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}
}
incrementAndGet() 메소드 내부에서 CAS 알고리즘의 로직을 구현하고 있다. getAndAddInt() 내부에서는 weakCompareAndSetInt() 메소드를 호출하여 메모리에 저장된 값과 현재 값을 비교하여 동일하다면, 메모리에 변경한 값을 저장하고 true를 반황하여 while문을 빠져 나온다.
추가로 눈 여겨 볼 점은 value 변수에 volatile 키워드가 붙은 것이다. 해당 키워드는 원자성 문제는 해결해 주지 않고 가시성 문제만 해결해 주므로 해당 공유 변수에 동시 쓰기가 발생하면 동기화 문제가 발생할 수 있다. 그런데, 사실 위 코드만 보면 어차피 AtomicInteger 클래스는 가시성 문제와 원자성 문제를 해결하는 CAS 알고리즘을 사용하는 메소드만 있는 것처럼 보인다.
class AtomicInteger {
private volatile int value;
public AtomicInteger(int initialValue) {
value = initialValue;
}
public AtomicInteger() {
}
public final int get() {
return value;
}
public final void set(int newValue) {
value = newValue;
}
...
}
하지만 AtomicInteger를 보면 CAS 알고리즘을 사용하지 않고 공유 변수를 읽거나 쓰는 작업이 있다. 이때 get() 과 set() 은 그 자체로 atomic 연산이므로 원자성 문제가 발생하지 않으므로 volatile을 통해 가시성 문제만 해결해 주는 것이다. 단순 대입 연산은 원자 연산임을 기억하자.
출처
- https://rightnowdo.tistory.com/entry/JAVA-concurrent-programming-Atomic원자성
- https://n1tjrgns.tistory.com/244
- https://javaplant.tistory.com/23
- https://beomseok95.tistory.com/225
- https://velog.io/@syleemk/Java-Concurrent-Programming-가시성과-원자성
- https://didrlgus.github.io/java/05-post/#atomic과-cas
예상 면접 질문 및 답변
synchronized의 문제점은?
synchronized는 스레드가 해당 블록에 lock을 걸면 lock에 접근하는 스레드들은 Blocking되기 때문에 성능 저하로 이어진다. 스레드가 Blocking 상태에 들어가면 아무 작업도 하지 못해 자원이 낭비되고, 상태가 변경되는 동안에도 시스템의 자원을 사용하기 때문이다.
atomic type에 대해 설명
atomic type은 멀티 스레드 환경에서 원자성을 보장하기 위한 개념이다. CAS 알고리즘을 통해 non-blocking하면서 가시성과 원자성을 보장해 동기화 문제를 해결한다.
CAS 알고리즘에 대해 설명
CAS 알고리즘은 현재 스레드가 가지고 있는 기존값과 메모리가 가지고 있는 값을 비교해 같은 경우 변경할 값을 메모리에 반영하고 true를 반환한다. 다른 경우에는 변경값이 반영되지 않고 false를 반환한 다음 재시도를 하는 방식으로 동작한다. CAS 알고리즘을 통해 가시성과 원자성 문제를 해결할 수 있다.
'스터디 > Java 스터디' 카테고리의 다른 글
| [Java] Synchronized Collection vs Concurrent Collection (0) | 2022.01.14 |
|---|---|
| [Java] String vs StringBuilder vs StringBuffer (0) | 2022.01.07 |
| [Java] 가변 객체 vs 불변 객체 (1) | 2021.12.31 |
| [Java] 뮤텍스, 세마포어, 모니터 (0) | 2021.12.30 |
| [Java] synchronized 키워드란? (1) | 2021.12.29 |
댓글