

[데이터베이스] B-Tree 인덱스와 다중 컬럼 인덱스
cs-study에서 스터디를 진행하고 있습니다.
B-Tree 인덱스란
- 트리의 노드가 한 방향으로 쏠리지 않게 재정렬을 통해, 각 노드 수의 밸런스를 유지하는 트리 형태의 자료구조이다.
- B-Tree는 데이터베이스의 인덱싱 알고리즘 가운데 가장 일반적으로 사용되고, 가장 먼저 도입된 알고리즘이다.
- B는 Binary(이진)이 아니라, Balanced(균형 잡힌)의 약자임을 기억하자.
- B-Tree는 컬럼의 원래 값을 변형하지 않고 인덱스 구조체 내에서는 항상 정렬된 상태를 유지한다.
- 전문 검색과 같은 특수한 요건이 아닌 경우, 대부분 인덱스는 B-Tree를 사용한다.
구조 및 특성
기본적인 B-Tree 구조
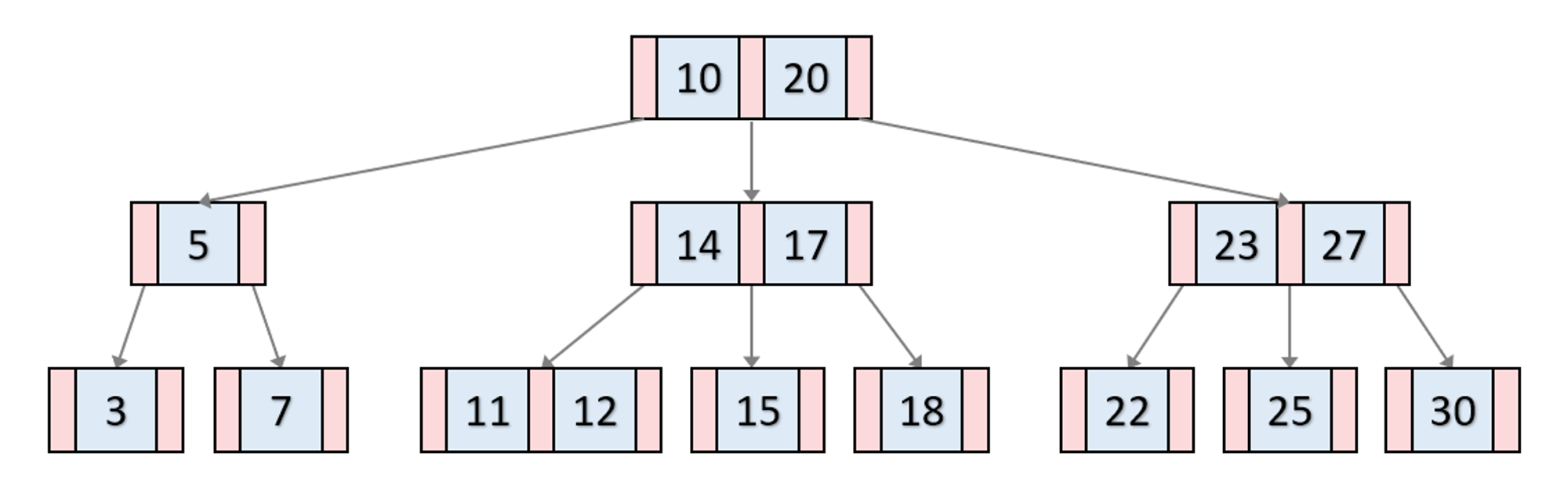
- 파란 부분은 노드의 key이며, 빨간 부분은 자식 포인터를 가리키는 포인터이다.
- 최상위에 있는 노드를 루트 노드라고 한다.
- 가장 하위에 있는 노드를 리프 노드라고 한다.
- 루트 노드도 리프 노드도 아닌 노드를 브랜치 노드라고 한다.
- key들은 노드 안에서 항상 정렬된 값을 가지며, 이진 검색 트리처럼 각 key들의 왼쪽 자식들은 항상 key보다 작은 값을, 오른쪽은 큰 값을 갖는다. 중요한 점은 가운데 자식 노드는 부모 노드 key의 사이 값을 갖는다.
- 노드가 균형 있게 구성되어 있어서, 최악의 경우이더라도 일관된 탐색 시간(
O(logN))을 갖는다.
실제 데이터베이스에서 사용하는 B-Tree 구조
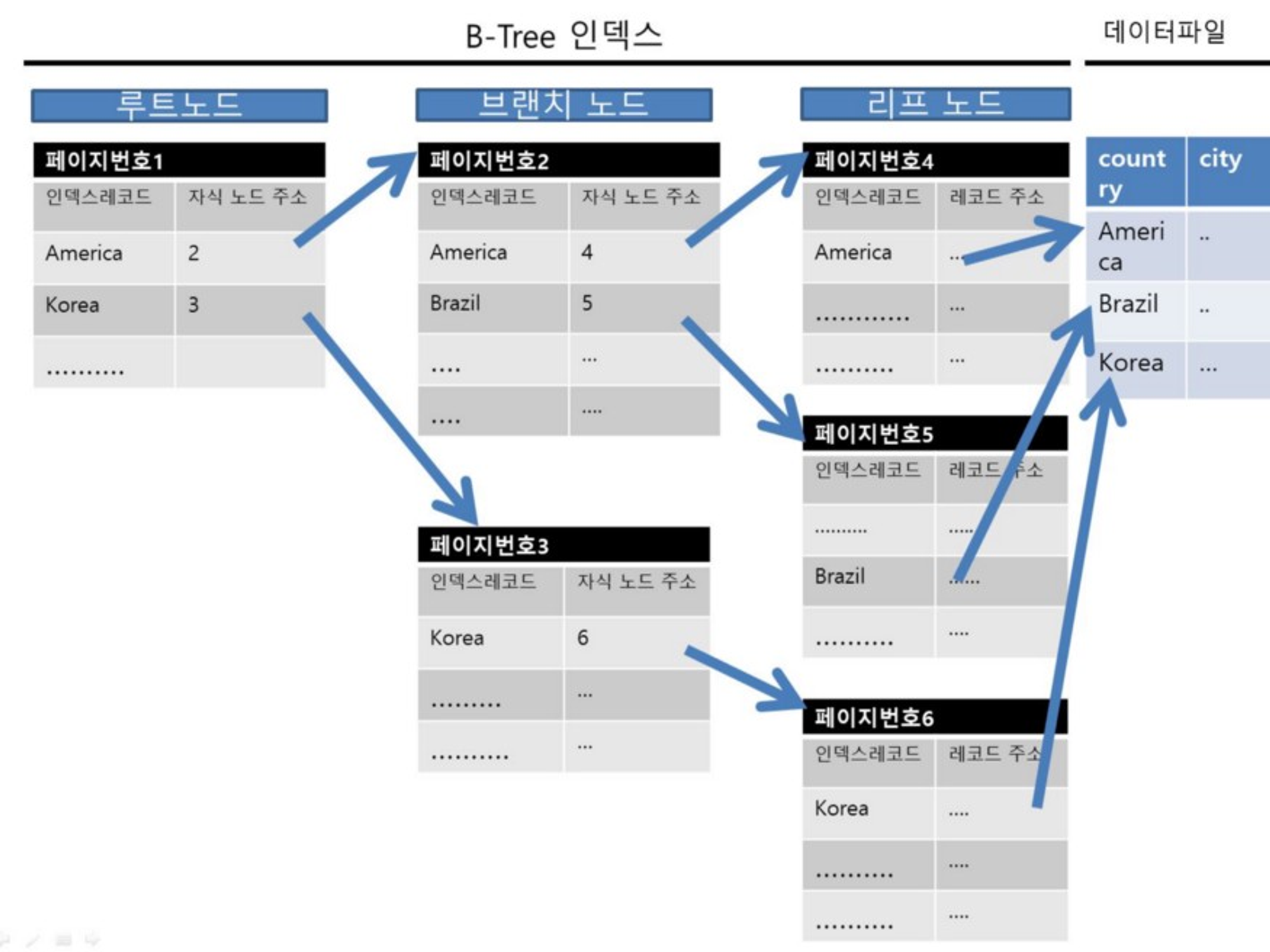
- 루트 노드와 브랜치 노드는 자식 노드의 주소를 가리키지만, 리프 노드는 실제 데이터 레코드를 찾아가기 위한 주소 값을 가리킨다. 인덱스와 실제 데이터가 저장된 데이터는 따로 관리하는 것을 알 수 있다.
- 인덱스 레코드를 key라고 생각하면 되고, 각각 정렬이 되어 있다.
- 다만 데이터 파일은 그림에서는 country 기준으로 정렬이 되었지만, 대부분 RDBMS의 데이터 파일은 특정 기준으로 정렬이 되어 있지 않다.
- 단 테이블에 데이터를 삽입만 하면 정렬된 것처럼 보이겠지만, 중간에 삭제 과정이 일어난다면 빈 공간에 데이터를 삽입하므로 임의의 순서가 된다.
- 예외적으로 InnoDB 테이블에서 레코드는 PK 기준으로 정렬되어 저장된다.
MyISAM vs InnoDB
[MyISAM]
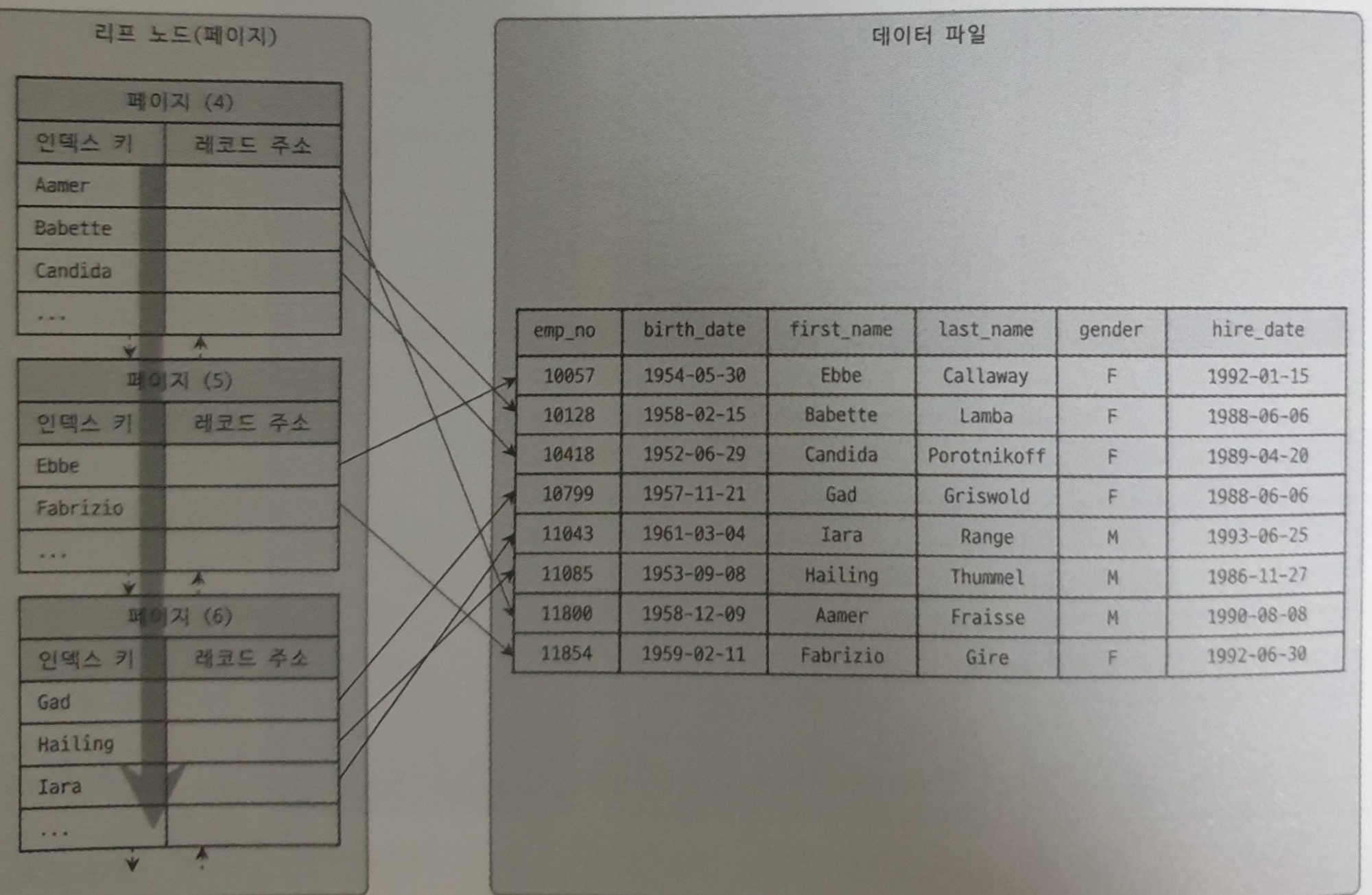
- MyISAM 테이블의 인덱스 리프 노드를 보면 레코드 주소가 있고, 이 레코드 주소는 MyISAM의 ROWID를 가리키고 있다. ROWID는 데이터의 물리적인 주소 값을 의미한다.
[InnoDB]
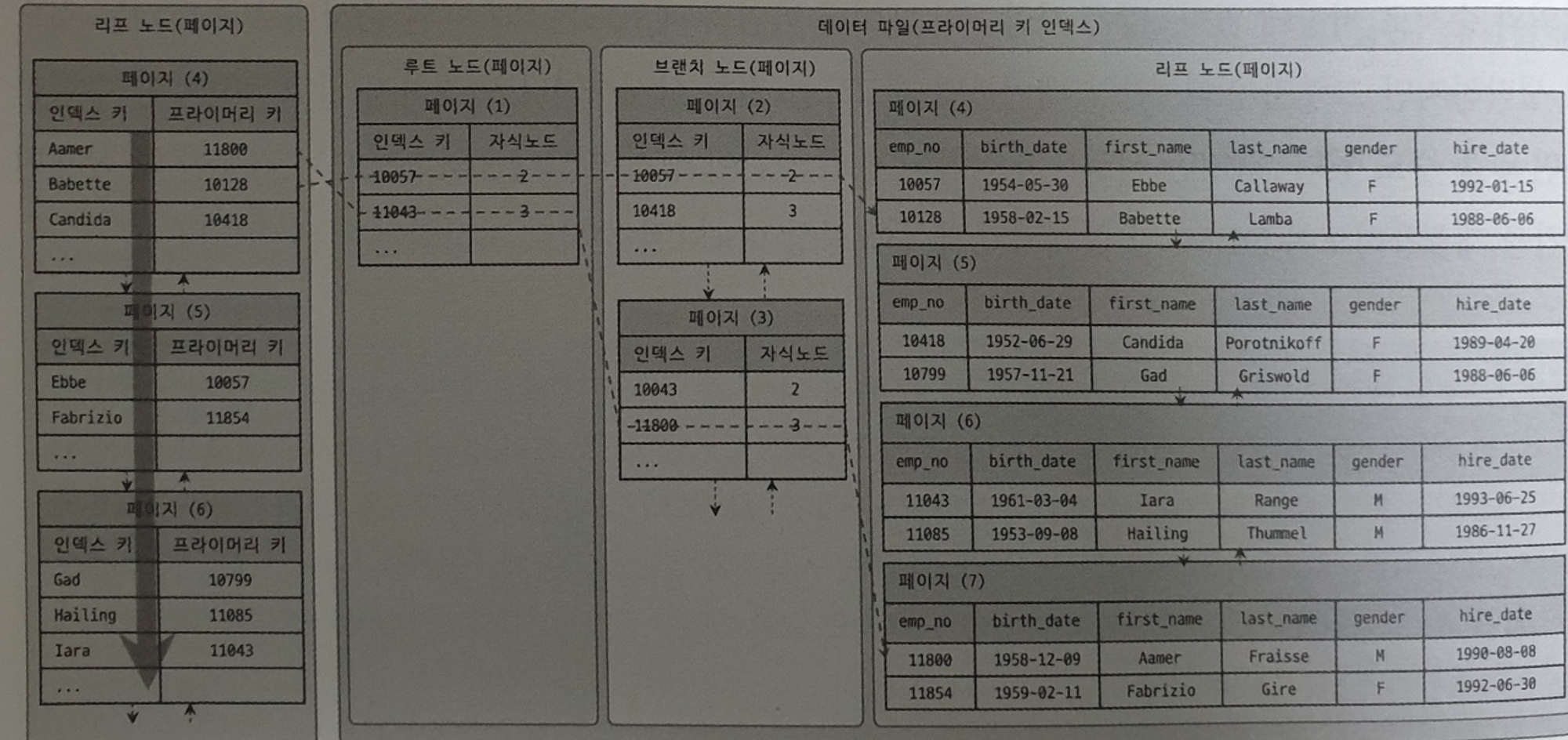
- InnoDB 테이블의 인덱스 리프 노드를 보면 레코드 주소 대신 PK가 있는데, 이 PK가 ROWID의 역할을 수행한다.
- MyISAM 테이블은 세컨더리 인덱스(PK 외의 다른 컬럼이 인덱스로 설정된 인덱스)가 물리적인 주소를 가지는 반면, InnoDB 테이블은 PK를 주소처럼 사용하므로 논리적인 주소를 갖는다고 한다.
- InnoDB 테이블은 인덱스를 통해 인덱스를 읽을 때 데이터 파일을 바로 찾아가지 못하고, 인덱스에 저장되어 있는 PK 값을 이용해 PK 인덱스(PK 컬럼이 인덱스로 설정된 인덱스)을 한 번 더 검색한 후 PK 인덱스의 리프 페이지에 저장되어 있는 레코드를 읽는다.
- 즉 InnoDB 스토리지 엔진에서는 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해 PK 인덱스 검색을 한 번더 수행한다.
- 이 구조로 인해 InnoDB 스토리지 엔진의 성능이 무조건 떨어질 것 같지만, 장단점이 있는데 이 부분은 추후 설명한다.
B-Tree 인덱스 키 추가 및 삭제
인덱스 키 추가
- B-Tree 상의 적절한 위치에 key 값을 저장한다.
- 저장될 위치가 결정되면 레코드의 키 값과 대상 레코드의 주소 정보를 리프 노드에 저장한다.
- 리프 노드가 꽉 찼다면 리프 노드를 분리한다.
- 이 과정 때문에 새로운 키를 추가하는 작업이 일반 트리에 비해 비용이 많이 든다.
- 다만 일반 트리는 데이터가 한 쪽에 쏠려서 극단적으로 List와 같아질 수 있다는 단점이 있다.
- 이 과정 때문에 새로운 키를 추가하는 작업이 일반 트리에 비해 비용이 많이 든다.
- 평균적으로 일반 테이블에 레코드를 추가하는 작업 비용을 1이라고 하면, 해당 테이블의 인덱스에 키를 추가하는 작업 비용은 1.5 정도 든다.
인덱스 키 삭제
- 해당 키 값이 저장된 리프 노드를 찾아서 삭제 마크만 취한다.
인덱스 키 변경
- 인덱스의 키 값은 그 값에 따라 저장될 리프 노드의 위치가 결정되므로 키 값이 변경되는 경우에 단순히 키 값만 변경하는 것은 불가능하다.
- 기존 키 값에 삭제 마크를 취하고, 새로운 키를 노드에 추가한다. (삭제 + 추가)
B-Tree 인덱스 사용에 영향을 미치는 요소
인덱스 키 값의 크기
- InnoDB 스토리지 엔진은 디스크에 데이터를 저장하는 기본 단위를 페이지 또는 블록이라고 하며, 디스크의 모든 읽기 및 쓰기 작업이 최소 작업 단위가 된다.
- 인덱스의 페이지 크기와 키 값의 크기에 따라 특정 노드의 자식 노드 개수가 정해진다.
- 인덱스 키 값이 커서 한 페이지에 인덱스 키를 300개 저장할 수 있다고 가정하자.
- 만약 SELECT 쿼리가 500개를 읽어야 한다면 최소 2번 이상 디스크로부터 데이터를 읽어야 한다.
- 디스크 IO 횟수가 많아지면 성능이 떨어진다.
- 결국 인덱스의 키 값은 작을수록 유리하다.
B-Tree 깊이
- 인덱스 키 값의 크기가 커지면 커질수록 하나의 인덱스 페이지가 담을 수 있는 인덱스 키 값의 개수가 적어지므로 B-Tree 깊이가 깊어진다.
- 깊이가 깊어진다는 뜻은 디스크 IO 횟수가 많아진다는 뜻이다.
선택도 (기수성)
- 인덱스 키 값 가운데 유니크한 값의 수를 의미한다.
- 전체 인덱스 키 값이 100개고, 유니크한 값의 수가 10개라면 기수성은 10이다.
- 인덱스는 선택도가 높을 수록 검색 대상이 줄어들기 때문에 그만큼 빠르게 처리된다.
이번에는 기수성과 관련된 예제를 살펴 보자. 예제는 다음 쿼리를 실행할 때 기수성의 값에 따라 성능 차이를 비교할 것이다.
-- tb_test 테이블에는 1만 건의 레코드가 있다.
-- 국가와 도시가 중복되어 저장되지 않는다고 가정.
SELECT * FROM tb_test WHERE country = 'KOREA' AND city = 'SEOUL';
[country 컬럼의 유니크 값이 10개]
전체 레코드 건수를 유니크한 값의 개수로 나눠보면 하나의 키 값으로 검색했을 때 대략 몇 건의 레코드가 일치할지 예측할 수 있다. 즉, 이 케이스의 tb_city 테이블에서는 country = 'KOREA' 라는 조건으로 인덱스를 검색하면 1000건 (10,000 / 10)이 일치한다고 예상할 수 있다.
그런데 실제 인덱스를 통해 검색된 1000건 가운데 city = 'SEOUL' 인 레코드는 1건이므로 999건은 불필요하게 읽은 것이다.
[country 컬럼의 유니크 값이 1000개]
위와 마찬가지로 예측 값은 10건 (10,000 / 1,000)이므로 실제 인덱스를 통해 검색된 10건 가운데 불필요한 레코드는 9건만 존재한다. 즉 유니크 값이 높을 수록 불필요하게 검색되는 레코드의 양이 감소하므로 성능이 향상된다.
읽어야 하는 레코드의 건수
- 일반적인 DBMS의 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이 테이블에서 직접 레코드 1건을 읽는 것보다 4 ~ 5배정도 비용이 드는 작업이라고 예측한다.
- 즉 인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20 ~ 25%를 넘어서면 인덱스를 사용하지 않고 일반 테이블 검색하는 것이 좋다.
B-Tree 인덱스를 통한 데이터 읽기
인덱스 레인지 스캔
- 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식이다.
- 검색하려는 값의 수나 검색 결과 레코드 건수와 관계 없이 레인지 스캔이라고 부른다.
- 루트 노드에서부터 비교를 시작해 브랜치 노드를 거치고 최종적으로 리프 노드까지 찾아 들어간다.
[검색하려는 값이 1개]
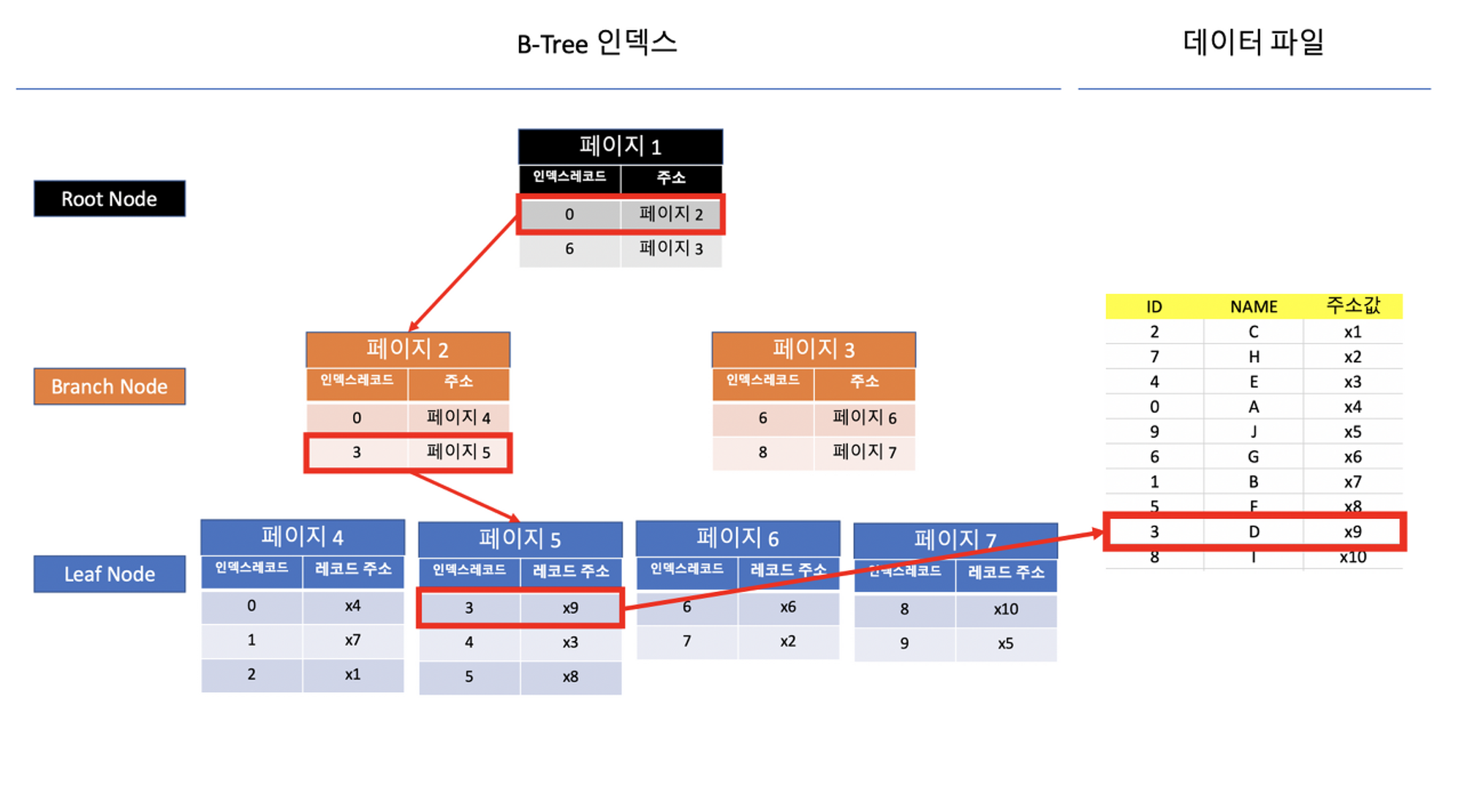
- ID가 3인 레코드를 찾는다고 가정할 때, 루트 노드로 접근하여 인덱스 레코드를 확인한다.
- 인덱스 레코드(key)를 확인해 보니, 0부터 5까지는 페이지 2에 저장되어 있는 것을 알 수 있다.
- 브랜치 노드로 내려가서 페이지 2로 접근한다.
- 페이지 2에서 3부터 5까지는 페이지 5에 저장되어 있는 것을 확인한다.
- 리프 노드로 내려가서 페이지 5로 접근한다.
- 리프 노드에는 디스크에 저장되어 있는 물리적인 주소가 있다.
- 리프 노드에서 ID가 3인 레코드를 찾고, 레코드 주소인 x9를 활용하여 디스크에 있는 데이터를 읽어 들인다.
[범위 검색]
SELECT * FROM employees WHERE first_name BETWEEN 'Ebbe' AND 'Gad';
위 쿼리를 통해 성씨가 ‘Ebbe’부터 ‘Gad’ 사이인 근로자를 검색한다.
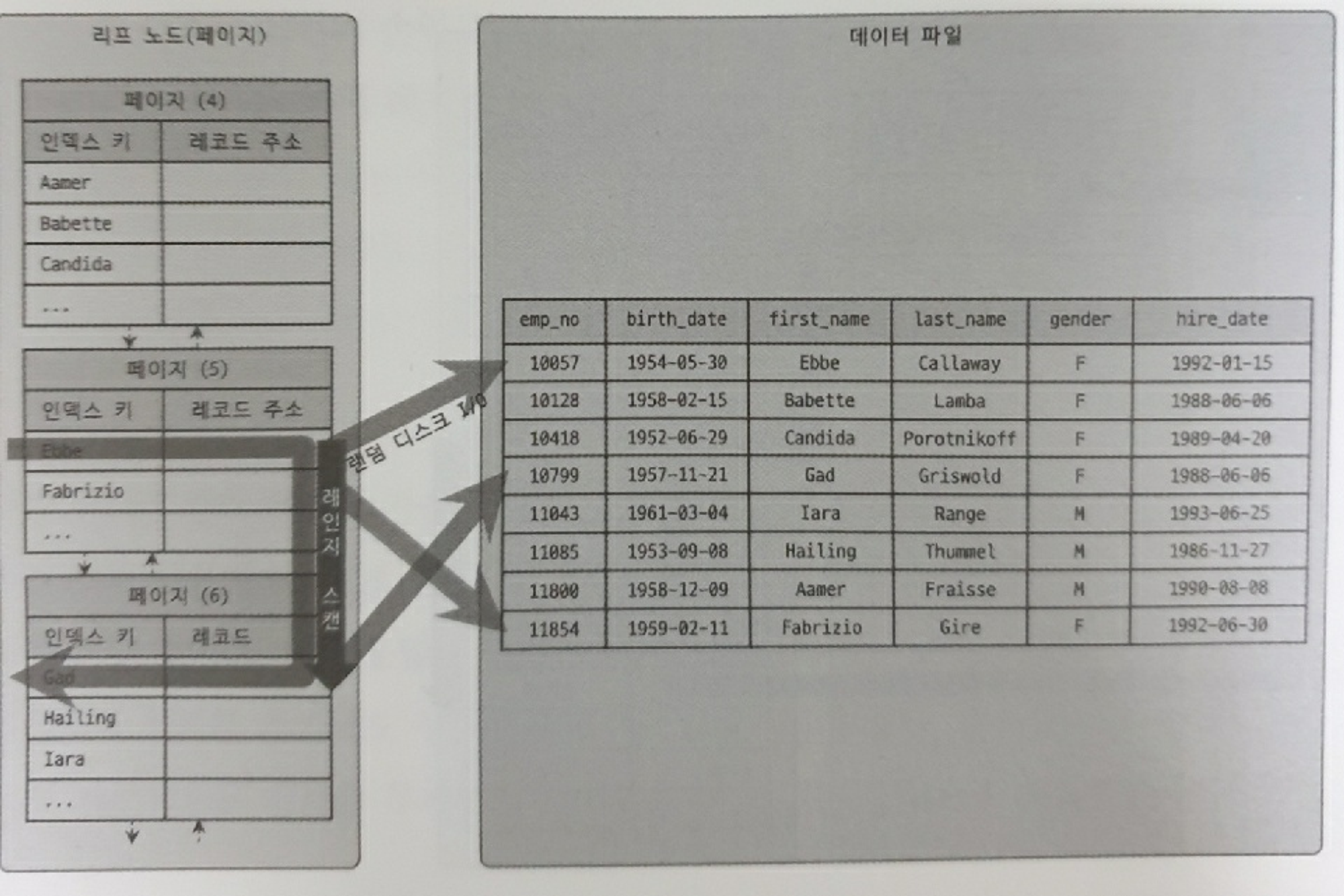
- B-tree 인덱스에서 루트 노드와 브랜치 노드를 이용해 스캔 시작 위치를 검색하고, 그 지점부터 필요한 방향으로 인덱스를 읽어 나간다.
- 인덱스는 자체 정렬 특성이 있다.
- 리프 노드에서 저장된 레코드 주소로 데이터 파일의 레코드를 읽어 오는데, 레코드 한 건 한 건 단위로 랜덤 I/O가 발생한다.
- 그래서 인덱스를 통해 읽어야 할 데이터가 20~25%를 넘으면 순차 I/O를 사용한 테이블 풀 스캔이 낫다고 하는 것이다.
인덱스 풀 스캔
- 인덱스의 처음부터 끝까지 모두 읽는 방식이다.
- 쿼리의 조건절에 사용된 컬럼이 첫 번째 컬럼이 아닌 경우 사용된다.
- ex) 인덱스는 (A, B, C) 컬럼의 순서로 만들어져 있지만, 쿼리의 조건절은 B 컬럼이나 C 컬럼으로 검색
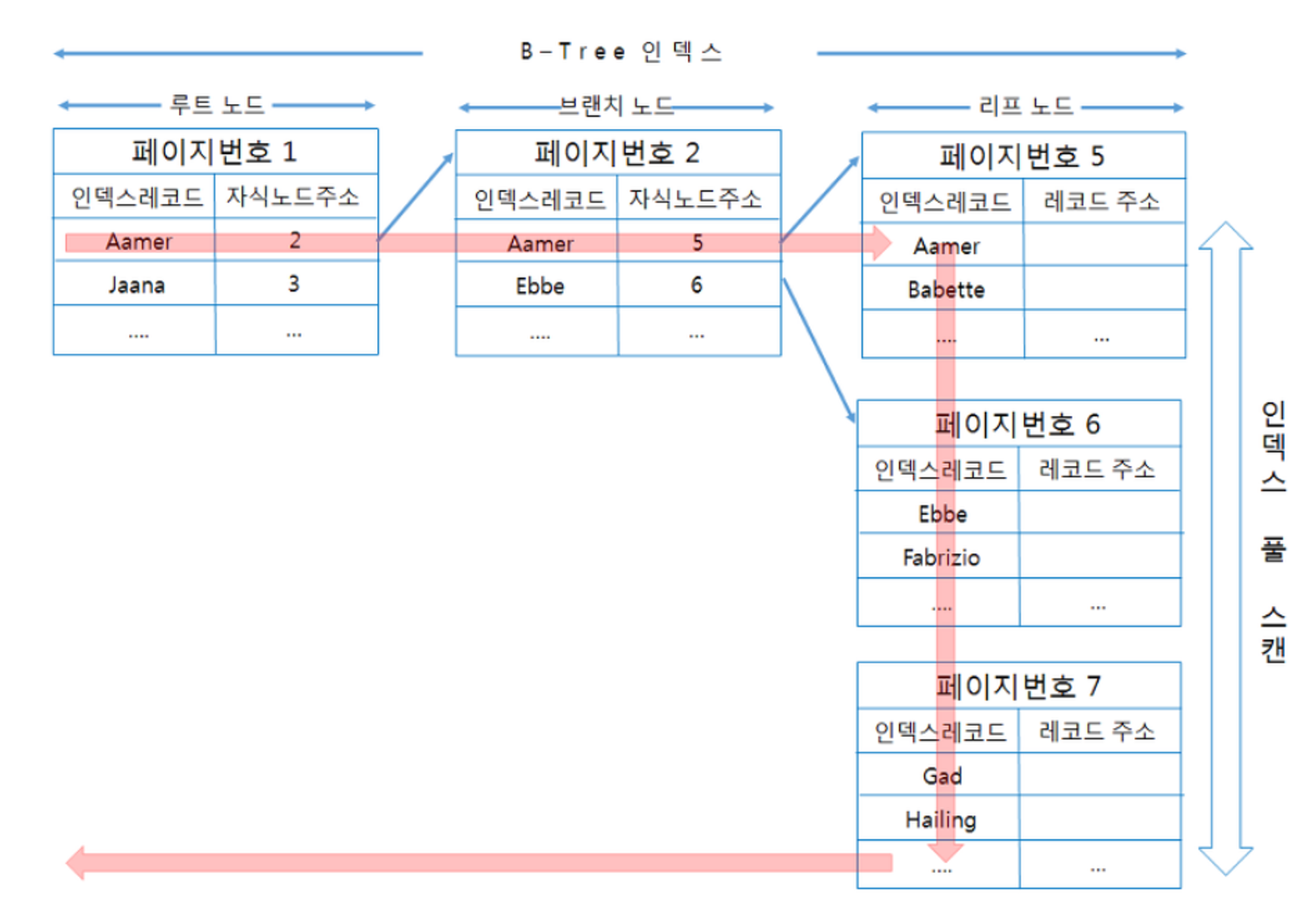
- 루트 노드의 첫 번째 인덱스 레코드와 이어진 브랜치 노드를 거쳐 리프 노드로 이동한다.
- 해당 리프 노드의 첫 번째 페이지의 인덱스 레코드 방향부터 아래로 탐색한다.
- 인덱스의 전체 크기는 테이블의 전체 크기보다 훨씬 작은 경우가 많으므로 풀 테이블 스캔보다는 적은 I/O로 쿼리를 처리할 수 있다.
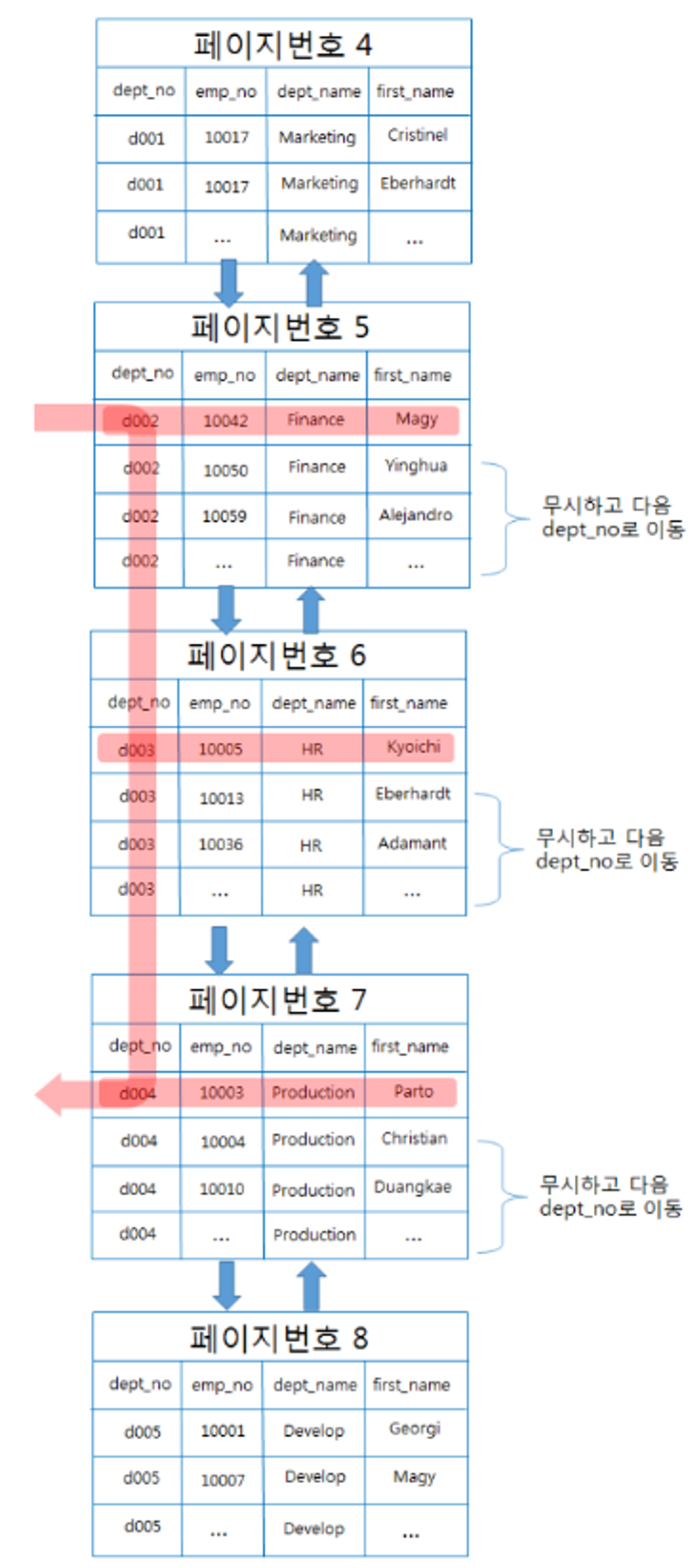
루스 인덱스 스캔
- 루스 인덱스 스캔이란 말 그대로 느슨하게 또는 듬성듬성하게 인덱스를 읽는 것을 의미한다.
- 인덱스 레인지 스캔과 비슷하게 동작하지만 중간마다 필요하지 않은 키 값은 무시한다.
- 일반적으로
group by또는max등의 함수에 대해 최적화할 때 사용한다.
select dept_no, MIN(emp_no)
from dept_emp
where dept_no between 'doo2' and 'd004'
group by dept_no;
dept_emp 테이블은 dept_no와 emp_no 2개의 컬럼으로 인덱스를 구성하고 있다고 가정하며, 이 인덱스는 (dept_no, emp_no)를 기준으로 정렬이 되어 있다. 즉 특정 dept_no 그룹 별로 처음에 있는 emp_no만 읽으면 된다. 즉, 인덱스에서 where 조건을 만족하는 범위 전체를 다 스캔할 필요가 없다는 것을 옵티마이저는 알고 있으므로 중간 중간 조건에 맞지 않으면 건너 뛴다.
다중 컬럼 인덱스
- 두 개 이상의 컬럼으로 구성된 인덱스를 다중 컬럼 인덱스라고 한다.
- 멀티 컬럼 인덱스, 복합 컬럼 인덱스, Concatenated Index라고도 부른다.
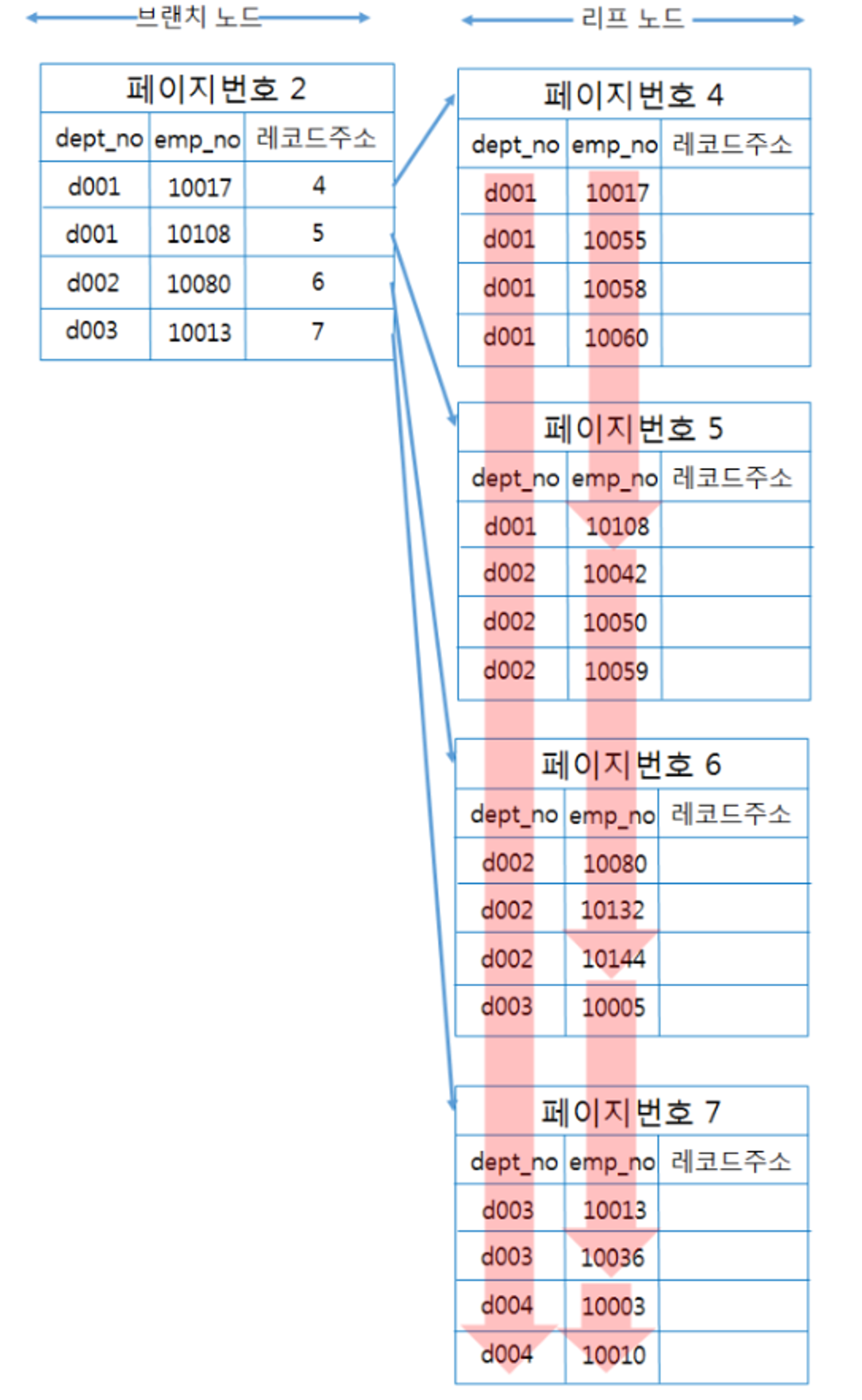
주의 사항
- 다중 컬럼 인덱스에서 중요한 것은 인덱스의 두 번째 컬럼은 첫 번째 컬럼에 의존해서 정렬되어 있다는 것이다. 즉, 두 번째 컬럼은 첫 번째 컬럼이 똑같은 레코드에서만 의미가 있다.
- 따라서 다중 컬럼 인덱스에서는 컬럼의 위치(순서)가 상당히 중요하며 신중하게 결정해야 한다.
=조건과 같이 개수가 적은 데이터를 조회하는 컬럼을 다중 컬럼 인덱스 앞 쪽에 설정하고, 범위 검색과 같이 개수가 많은 데이터를 조회하는 컬럼을 다중 컬럼 인덱스 뒤족에 설정해야 한다.
- 단일 컬럼 인덱스보다 더 비효율적으로 Insert/Update/Delete를 수행하므로 가급적 업데이트가 안 되는 값을 선정해서 사용하는 것이 좋다.
언제 사용할까?
- 데이터를 조회할 때 단일 인덱스를 여러 개를 사용해야 하는 경우가 많다면 다중 컬럼 인덱스를 고려해 본다.
- A, B 컬럼을 바탕으로 데이터 탐색을 자주 한다고 가정해 보자.
- A, B 각각 인덱스 설정
- A 컬럼과 B 컬럼을 보고 둘 중에 어떤 컬럼의 수가 빠르게 검색되는지 판단하고 더 빠른 쪽을 먼저 검색하고 그 다음 컬럼을 검색한다.
- (A, B) 한꺼번에 인덱스 설정
- 인덱스 안에 A, B 정보가 있으므로 바로 검색이 가능하므로 위 방식보다 더 빠르다.
- 다만 where 조건문에 B만 사용하면 인덱스를 타지 않는다. B는 A에 의존적으로 정렬이 되기 때문이다. (반대로 where 조건문에 A만 사용하는 것은 괜찮다.)
- A, B 각각 인덱스 설정
출처
- https://12bme.tistory.com/138
- https://swknight13.medium.com/dbms-의-인덱스-b-tree-4ff039dca22
- https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree
- https://velog.io/@mu1616/데이터베이스-인덱스-Index
- https://spiderwebcoding.tistory.com/6
- Real MySQL
예상 면접 질문 및 답변
B-Tree 구조에 대해 설명하라.
트리의 노드가 한 방향으로 쏠리지 않게 재정렬을 통해, 각 노드 수의 밸런스를 유지하는 트리 형태의 자료구조이다.
B-Tree의 장점과 단점에 대해 설명하라.
장점
노드가 균형 있게 구성되어 있어서, 최악의 경우이더라도 일관된 탐색 시간(O(logN))을 가질 수 있다.
단점
재정렬을 해야 하는 작업으로 인해, 노드를 삽입 하거나 삭제 할 때 일반적인 트리보다 성능이 떨어진다.
인덱스는 어떻게 작동하는가?
일반적으로 B-Tree 자료 구조를 사용하여 검색해야 할 값을 루트 노드에서부터 비교를 시작해 브랜치 노드를 거치고 최종적으로 리프 노드까지 찾아 들어간다. 그리고 리프 노드의 레코드 주소를 사용하여 실제 데이터 파일에 존재하는 레코드를 읽는다.
멀티 컬럼 인덱스는 언제 사용하는가?
데이터를 조회할 때 단일 인덱스를 여러 개를 사용해야 하는 경우가 많다면 다중 컬럼 인덱스를 고려해 본다. 예를 들어 A, B 컬럼을 바탕으로 데이터 탐색을 자주 할 경우 A, B에 단일 인덱스에 걸려 있는 상태에서 조회하는 성능보다 A, B에 다중 컬럼 인덱스가 걸려 있는 경우에 데이터 액세스가 줄어들어 성능이 더 좋기 때문이다.
멀티 컬럼 인덱스를 사용할 때 주의할 점은?
- 다중 컬럼 인덱스에서 중요한 것은 인덱스의 두 번째 컬럼은 첫 번째 컬럼에 의존해서 정렬되어 있다는 것이다. 즉, 두 번째 컬럼은 첫 번째 컬럼이 똑같은 레코드에서만 의미가 있다. 그래서 컬럼의 순서를 신중하게 결정해야 한다. 가령,
=조건과 같이 개수가 적은 데이터를 조회하는 컬럼을 다중 컬럼 인덱스 앞 쪽에 설정하고, 범위 검색과 같이 개수가 많은 데이터를 조회하는 컬럼을 다중 컬럼 인덱스 뒤쪽에 설정하는 것이 좋다. - 단일 컬럼 인덱스보다 더 비효율적으로 Insert/Update/Delete를 수행하므로 가급적 업데이트가 안 되는 값을 선정해서 사용하는 것이 좋다.
'스터디 > CS 스터디' 카테고리의 다른 글
| [데이터베이스] NoSQL - What is NoSQL (0) | 2021.12.26 |
|---|---|
| [데이터베이스] 잠금이란? (0) | 2021.12.25 |
| [데이터베이스] MySQL 엔진의 잠금 (0) | 2021.12.19 |
| [데이터베이스] 트랜잭션 기초 (0) | 2021.12.19 |
| [데이터베이스] NoSQL - What are Data Models (0) | 2021.12.17 |
댓글